 FedFTG & Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
FedFTG & Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
# FedFTG: Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
# 摘要
联邦学习(Federated Learning, FL)是一种新兴的分布式学习范式,具有隐私保护的约束。数据异质性是FL中的主要挑战之一,导致收敛速度变慢和性能下降。大多数现有方法仅通过限制客户端的本地模型更新来应对异质性挑战,忽略了全局模型直接聚合引起的性能下降。相反,我们提出了一种无数据的知识蒸馏方法,用于在服务器上微调全局模型(FedFTG),以缓解直接模型聚合的问题。具体而言,FedFTG通过生成器探索本地模型的输入空间,并利用其将本地模型的知识传递到全局模型。此外,我们提出了一种难样本挖掘方案,以实现有效的知识蒸馏贯穿整个训练过程。此外,我们开发了定制的标签采样和类别级别集成,以最大化知识的利用率,隐式地减轻客户端之间的分布差异。大量实验表明,FedFTG显著优于现有最先进的FL算法,并且可以作为增强FedAvg、FedProx、FedDyn和SCAFFOLD的强大插件。
愿论文地址:https://arxiv.org/abs/2203.09249
# 1.引言
随着数据量的爆炸性增长以及严格的隐私保护政策的实施,由于高带宽成本和隐私泄露风险,随意的数据传输和聚合逐渐变得不可接受。近年来,联邦学习(Federated Learning,FL)[30, 31] 被提出,以替代传统的高度集中式学习模式,并保护数据隐私。它已经成功应用于实际任务中,如智慧城市 [16, 34, 43]、医疗健康 [8, 26, 27] 和推荐系统 [9, 10] 等。
FL 面临的主要挑战之一是数据的异质性,也就是客户端的数据是非独立同分布(Non-IID)的。已经证实,传统的联邦学习算法 FedAvg [30] 在这种情况下会导致本地模型发生偏移,并严重遗忘全局知识,进而导致性能下降和收敛速度变慢 [14, 19, 21]。这是因为本地模型仅基于本地数据更新,即最小化本地经验损失。然而,最小化本地经验损失在非独立同分布的 FL 环境中,与最小化全局经验损失存在根本性矛盾 [1, 24, 29]。
为了解决数据异质性问题,大多数现有方法(如 FedProx [23]、SCAFFOLD [18]、FedDyn [1] 和 MOON [22])通过限制本地模型更新方向来对齐本地和全局的优化目标。最近,FedGen [44] 提出了一种轻量级生成器,用于生成伪特征,并将其广播给客户端,以调节本地训练。然而,所有这些方法仅通过简单的模型聚合来获得服务器中的全局模型,忽略了本地知识的不兼容性,导致全局模型中的知识遗忘。此外,[37] 研究表明,直接聚合模型会大大降低性能,而微调则可以显著提高精度。这些观察结果促使我们在服务器中基于本地模型的知识微调聚合后的全局模型。
另一方面,仅在服务器中聚合本地模型忽视了服务器丰富的计算资源,这些资源可以在跨组织联邦学习(cross-silo FL)中得到充分利用,以提高 FL 性能 [17]。基于这些观察,我们提出了一种通过无数据的知识蒸馏(FedFTG)在线微调全局模型的新方法,该方法同时优化了模型聚合过程,并利用了服务器的强大计算能力。具体而言,FedFTG 通过服务器中的辅助生成器对本地模型的输入空间进行建模,然后生成伪数据,将本地模型中的知识传递到全局模型,以提升性能。为了在整个训练过程中有效进行知识蒸馏,FedFTG 迭代地探索数据分布中的难样本(hard samples),这些难样本会导致本地模型和全局模型之间的预测分歧。图1比较了 FedFTG 和 FedAvg。FedFTG 通过对难样本进行微调,纠正了模型聚合后的偏移。生成器和全局模型通过对抗训练方式在无数据的情况下进行训练,因此整个过程不会违反 FL 中的隐私政策。考虑到数据异质性场景中的标签分布偏移,我们进一步提出了自定义标签采样和类别级别集成技术,这些技术通过探索客户端的分布关联性,实现知识的最大化利用。
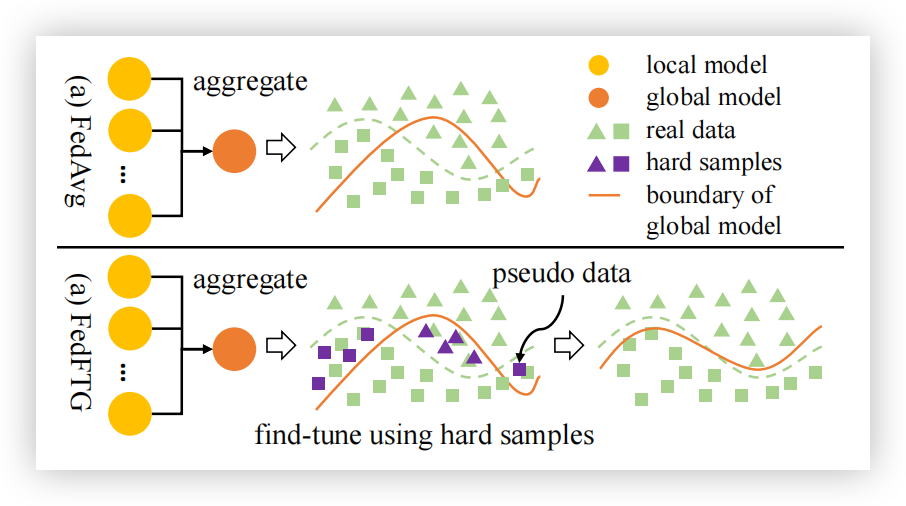
图1. FedAvg [30] 与 FedFTG 的比较。通过使用生成的难样本微调全局模型,FedFTG 缓解了模型聚合后性能下降的问题。
FedFTG 与现有的几种本地优化器(如 FedAvg、FedProx、FedDyn、SCAFFOLD 和 MOON)是正交的,因为它仅修改了服务器中全局模型的聚合过程。因此,FedFTG 可以无缝嵌入这些本地 FL 优化器中,利用它们的优势进一步提升 FedFTG 的性能。在各种设置下进行的大量实验验证了 FedFTG 相比于最先进的(SOTA)方法具有优越的性能。
本文的主要贡献如下:
- 我们提出了 FedFTG,通过无数据的蒸馏对服务器中的全局模型进行微调,同时增强了模型聚合步骤并利用了服务器的计算能力。
- 我们开发了难样本挖掘技术,以有效地将知识传递给全局模型。此外,我们提出了自定义标签采样和类别级别集成,以促进知识的最大化利用。
- 我们证明 FedFTG 与现有的本地优化器是正交的,可以作为一个强大且通用的插件,增强 FedAvg、FedProx、FedDyn、SCAFFOLD 和 MOON 的性能。
- 我们通过在五个基准上的大量实验,验证了 FedFTG 相比多种 SOTA 方法(包括 FedAvg、FedProx、FedDyn、SCAFFOLD、MOON、FedGen 和 FedDF)的优越性。
# 2. 相关工作
现有大量研究通过客户端选择 [4, 7, 15]、分割学习 [11, 39]、领域适应 [26, 33] 等方法提升联邦学习(FL)的全局性能。读者可以参考专著 [17, 38] 及其中引用的文献来了解该领域的最新进展。以下,我们主要总结与本文工作最相关的技术。
# 2.1联邦优化器
传统的 FL 算法,即 FedAvg [30],定期在服务器中聚合本地模型,并使用各自的数据更新本地模型。FedProx [23] 在本地子问题中添加了一个邻近项,以限制本地更新更接近初始(全局)模型。SCAFFOLD [18] 使用方差缩减技术来校正漂移的本地更新。FedDyn [1] 通过引入线性和二次惩罚项修改客户端的目标,以对齐全局和本地目标。总结来说,所有这些方法都专注于对齐本地和全局模型,以缩小本地训练中的分布偏移,而不像 FedFTG 直接提升全局模型。
# 2.2联邦学习中的知识蒸馏
借助无标签数据集,FedDF [25] 提出了一种用于模型融合的集成蒸馏方法,通过本地模型的平均对数值(logits)训练全局模型。FedAUX [35] 寻找一种用于本地模型的初始化,并通过(
# 2.3无数据知识蒸馏(DFKD)
DFKD 方法 [2, 6] 从预训练的教师模型生成伪数据,并使用这些数据将教师模型的知识传递给学生模型。通过最大化教师模型对伪数据的响应来生成数据。DeepImpression [32] 对教师模型的输出空间进行建模,并通过拟合输出空间恢复真实数据。DeepInversion [41] 通过正则化中间特征图的分布进一步优化伪数据。DAFL [2] 和 DFAD [6] 使用生成器高效生成数据,DAFL 通过最大化预测和特征层次的响应来优化生成器,DFAD 则采用对抗训练方案以有效利用教师模型中的知识。
FedGen [44] 也学习了一个轻量级生成器,以无数据的方式融合本地模型的知识,但其主要用于规范本地训练。此外,我们设计了难样本挖掘方案、自定义标签采样和类别级别的集成方法,以在数据异质性场景下有效地将本地模型的知识传递给全局模型。
# 算法 1:FedFTG

输入:
: 通信轮数; : 客户端数量; : 每轮中的活动客户端比例; : 客户端的数据集; : 分类器的参数; : 生成器的参数。
- 初始化模型参数
和 。 - 对于
执行: - 随机选择一个包含
个客户端的集合 ; - 并行地,对于
执行: - 使用 FedAvg、FedProx、FedDyn 和 SCAFFOLD 算法,更新本地模型
。
- 使用 FedAvg、FedProx、FedDyn 和 SCAFFOLD 算法,更新本地模型
- 更新服务器上的模型参数
和 。
- 随机选择一个包含
# 算法 2:服务器更新,第

输入:
: 服务器中的训练迭代次数; : 训练生成器和全局模型的内迭代次数; : 全局步长; : 服务器和生成器的模型参数; : 客户端模型参数; : 损失函数中的权重。
- 计算全局模型更新
,并更新 。 - 根据公式 (9) 计算
。 - 对于
执行: - 采样一批噪声和标签
; - 根据公式 (10) 计算
; - 对于
执行: - 根据公式 (8) 更新生成器
,以基于当前全局模型 挖掘难样本;
- 根据公式 (8) 更新生成器
- 对于
执行: - 根据公式 (8) 更新全局模型
,以从 中传递知识给 。
- 根据公式 (8) 更新全局模型
- 采样一批噪声和标签
- 返回
。
# 3. 方法
在本节中,我们介绍了一种新颖的联邦学习方法:FedFTG。在每轮通信中,FedFTG 随机选择一组客户端,并将全局模型广播给这些客户端。每个客户端使用全局模型初始化本地模型,并通过本地优化器对其进行训练。服务器随后收集本地模型,并将它们聚合成一个初步的全局模型。
与直接将聚合后的模型再次广播给各个客户端不同,FedFTG 在服务器中使用从本地模型中提取的知识对这个初步全局模型进行微调。具体而言,我们开发了一种无数据的知识蒸馏方法,通过难样本挖掘来有效地探索并将知识传递给全局模型。考虑到客户端中标签分布的偏移,我们提出了自定义标签采样和类别级别的集成策略,以促进更有效的知识利用。图 2 展示了服务器上的训练过程,相应的算法总结在算法 1 和算法 2 中。需要注意的是,FedFTG 与现有的本地模型训练优化方法(如 SCAFFOLD、FedAvg、FedProx 和 FedDyn)是正交的,能够与这些方法无缝结合。
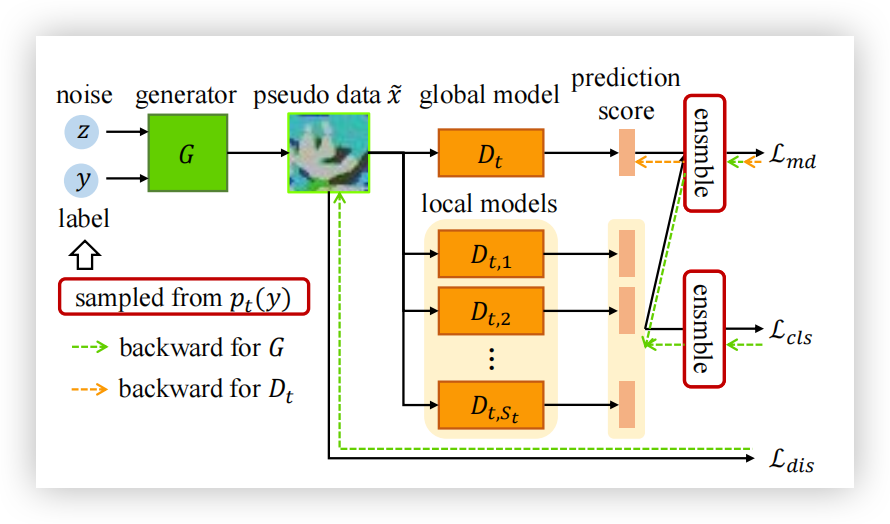
图 2. FedFTG 在服务器中的训练过程。在第
# 3.1. 无数据知识蒸馏与难样本挖掘用于全局模型微调
设
其中
为了解决上述优化问题,每轮通信
然而,在数据异构场景下,本地模型之间存在很大的漂移。因此,传统的梯度平均方法可能会丢失本地模型中的知识,导致更新后的全局模型性能远低于本地模型的表现 [45]。为了解决这个问题,我们提出了一种无数据的知识蒸馏方法来微调全局模型,使全局模型能够尽可能保留本地模型中的知识并保持其性能。
具体来说,服务器维护一个条件生成器
其中
如图 2 所示,我们将伪数据
其中
其中
通过最小化
# 3.11数据保真性与多样性约束
为了更好地从本地模型中提取知识,伪数据
其中,
这里的
然而,简单使用
其中,
# 3.12硬样本挖掘
使用
为了有效地利用本地模型中的知识并将其转移到全局模型中,我们探索了数据分布中的难样本,这些样本导致本地模型和全局模型之间的预测不一致。具体而言,我们通过
因此,FedFTG 在服务器端的总体目标被形式化为对抗学习方案:
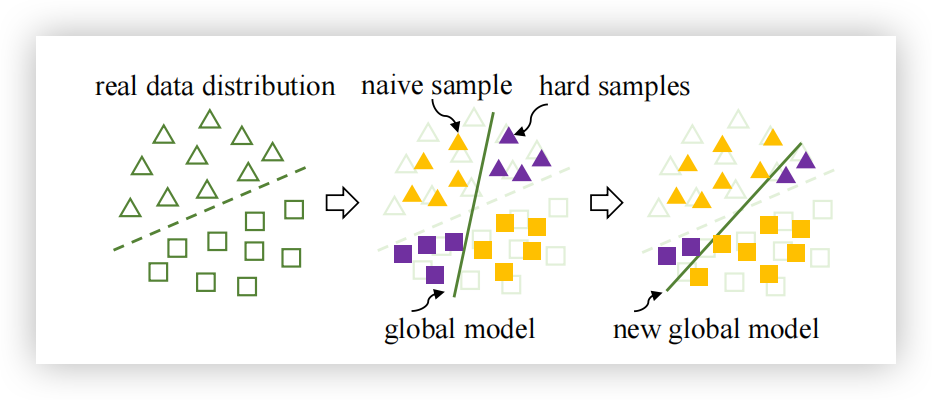
图 3. 难样本挖掘的可视化。通过探索数据分布中的难样本并微调全局模型,全局模型可以在训练过程中逐步得到修正。
# 3.2. 标签分布偏移自适应以实现高效的知识蒸馏
在数据异质性场景中,不同客户端的标签分布是不同的,即
自定义标签采样
在数据异质性场景中,本地客户端的数据集通常是类别不平衡的,甚至对于某些类别没有数据。已有研究证明,深度神经网络倾向于学习占多数的类别,而忽略占少数的类别[5]。因此,本地模型中少数类的数据信息可能是错误的,生成的伪数据无效且无法有效衡量模型差异。如果均匀地采样标签
其中,当条件为真时,
类别级集成
在知识蒸馏中广泛使用的集成方法对不同教师模型的知识分配相同的权重【25, 44】,即在公式 (3) 和公式 (5) 中,
这样,本地模型的知识可以根据其对各类的重要性灵活整合,从而 FedFTG 能够最大程度地利用本地模型中的知识。
# 4.实验
在本节中,我们通过实验证实了FedFTG的有效性。我们在第4.1节总结了实现细节,并在第4.2节将FedFTG与几种SOTA联邦学习(FL)算法进行比较。通过消融实验(第4.3节),验证了FedFTG各个组件的必要性。为了进一步验证FedFTG在真实世界FL应用中的效果,我们在第4.4节对三个真实世界数据集进行了性能评估。
代码地址:https://github.com/ZhangLin-PKU/FedFTG (opens new window)
# 4.1 实现细节
基线:我们将FedFTG与FedAvg [30]、FedProx [23]、SCAFFOLD [18]、FedDyn [1]、MOON [22]、FedGen [44] 和 FedDF [25] 进行比较。由于FedDF没有解释如何获得生成器,我们按照FedGen的方式进行训练。
数据集:我们使用CIFAR10和CIFAR100数据集[20]进行异构数据集划分测试FedFTG的有效性,这两个任务在FL场景中较为困难,并且在FL研究中被广泛采用。与现有工作[1, 12, 42]类似,我们使用Dirichlet分布
网络架构:对于CIFAR10和CIFAR100,我们使用ResNet18[13]作为基础骨干网络。对于FedFTG和FedDF,我们借鉴了DFAD[6]的生成器网络架构。对于FedGen,生成器网络由两个嵌入层(分别用于输入
超参数:对于所有方法,我们设置本地训练轮次
我们在补充材料中提供了详细的实现细节和额外的实验结果。
# 4.2. 性能比较
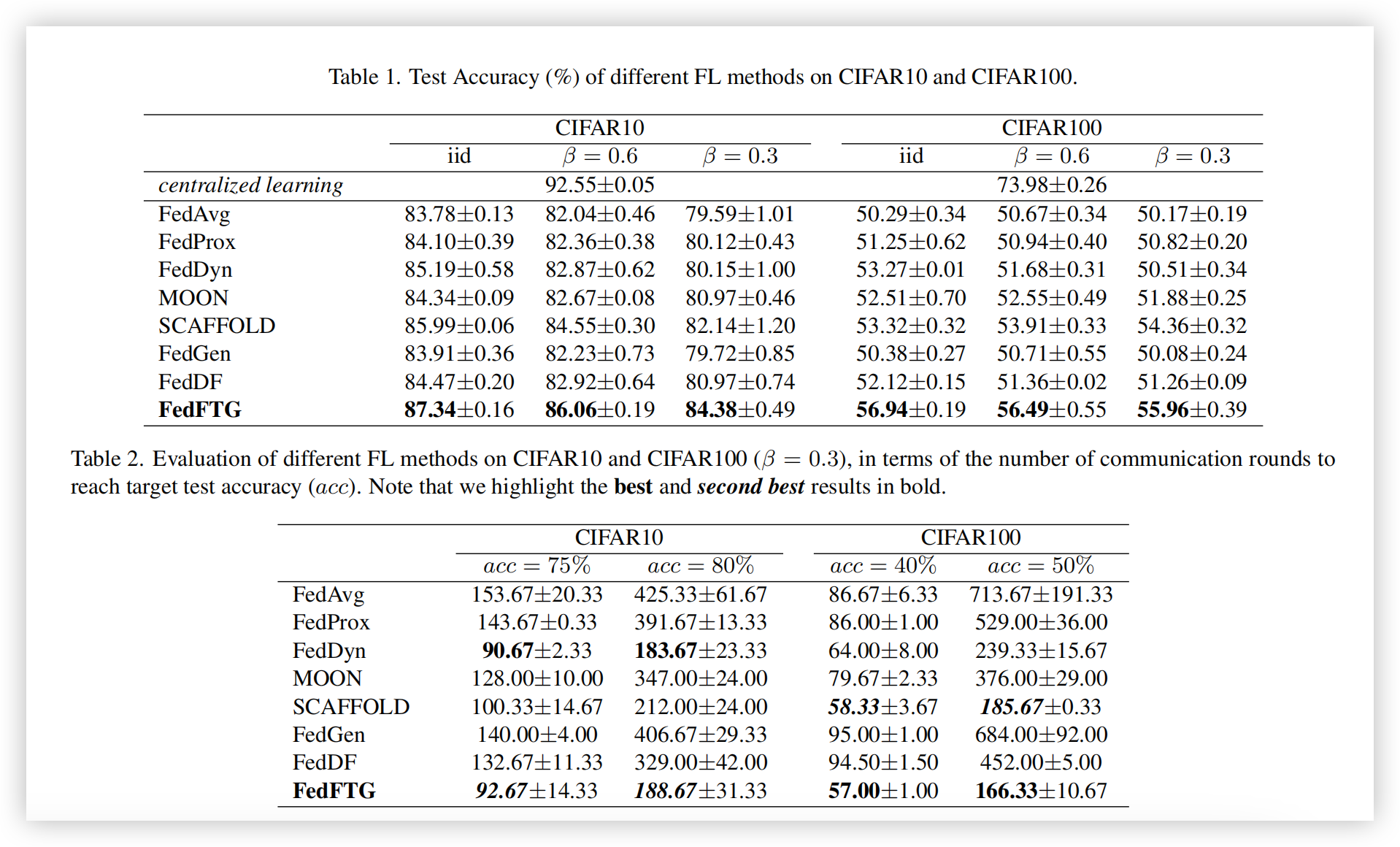
测试准确率:表1报告了所有算法在CIFAR10和CIFAR100数据集上的测试准确率。我们在第一行中提供了集中式学习的性能。所有实验均在3个随机种子上重复。在表1中,FedFTG在所有场景中都取得了最佳性能,至少比第二名(即SCAFFOLD)高出1.5%。FedDF也采用了无数据的知识蒸馏在服务器端提升全局模型性能,它超越了FedAvg和FedProx,并在某些情况下优于FedDyn和MOON,这进一步验证了“在服务器端微调全局模型”这一方案的优越性。然而,它的表现仍不及SCAFFOLD和FedFTG。FedGen相比于FedDF和FedFTG准确率更低,且在某些情况下仅比FedAvg略有性能提升。FedDF和FedGen的表现进一步验证了FedFTG中提出模块的有效性。
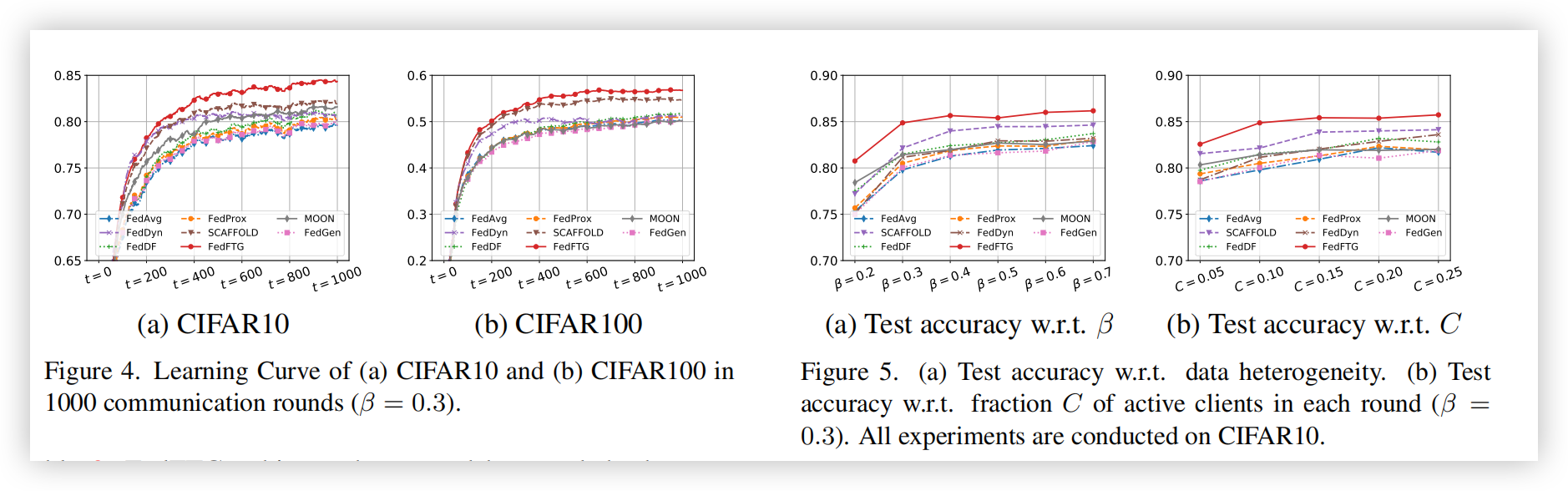
通信轮次:表2评估了不同FL方法达到目标测试准确率(CIFAR10为75%和80%,CIFAR100为40%和50%)所需的通信轮次。表2显示,FedFTG在CIFAR10上取得了第二好结果,而在CIFAR100上表现最佳。此外,FedFTG在所有场景中减少了其FL优化器(SCAFFOLD)所需的通信轮次。对于CIFAR10,尽管FedDyn使用更少的轮次来达到目标准确率,但其最终准确率远低于FedFTG,如表1所示。下文中,我们展示了使用FedDyn作为FedFTG优化器的结果,衍生方法FedDyn+FedFTG所需的轮次比FedDyn更少以达到目标准确率。图4展示了在1000个通信轮次中不同方法的学习曲线,其中FedFTG在1000轮后获得了显著的性能提升。尽管FedDyn在初期有更快的上升速度,但随着训练的进行,其上升趋势逐渐减慢,并且在CIFAR10和CIFAR100中分别在150和50轮后落后于FedFTG。
**数据异质性与部分客户端参与:**图5(a)显示了不同
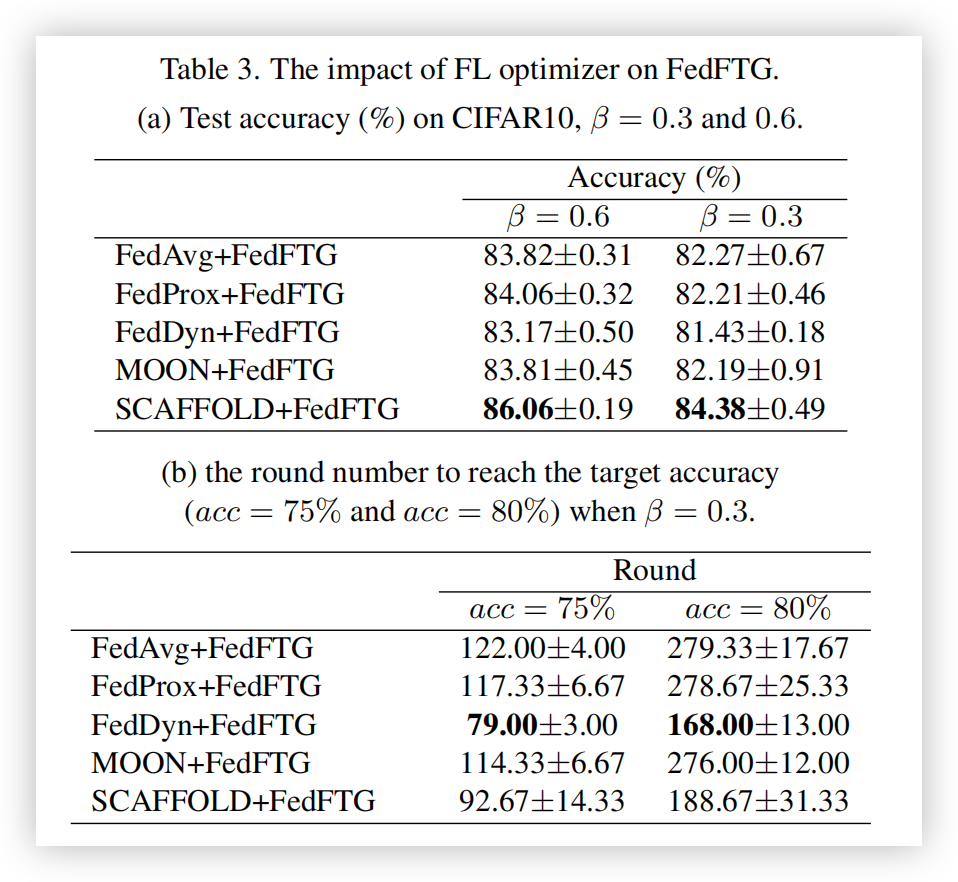
FedFTG与现有FL优化器的正交性
表3展示了FedFTG结合FedAvg、FedProx、FedDyn、SCAFFOLD和MOON优化器的性能。在表3中,SCAFFOLD+FedFTG在所有优化器中取得了最高的测试准确率。FedDyn+FedFTG在达到目标准确率的轮次上表现优于SCAFFOLD+FedFTG,这与表2中的结果一致,其中FedDyn所需轮次少于SCAFFOLD。通过对比表3与表1和表2,我们注意到,使用FedFTG可以大幅提升任何FL优化器的性能。这验证了FedFTG的有效性及其与现有优化器的正交性。此外,仅使用FedAvg+FedFTG作为本地优化器的表现已超过表1中的其他方法(除了SCAFFOLD)。
# 4.3 消融研究
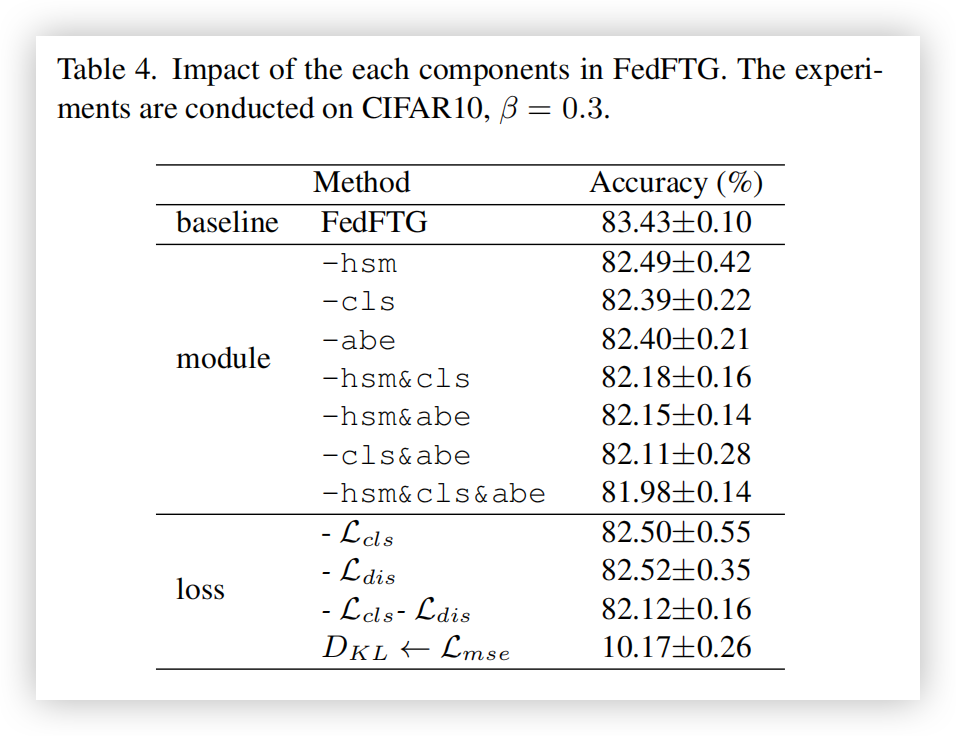
FedFTG 各组件的必要性:表 4 显示了 FedFTG 在 CIFAR10 数据集上经过 500 轮通信训练(
对于损失函数也是类似的趋势:移除单个损失函数会导致性能下降,而移除多个损失函数会进一步加剧这种下降。值得注意的是,如果用均方误差(Mean Squared Error,
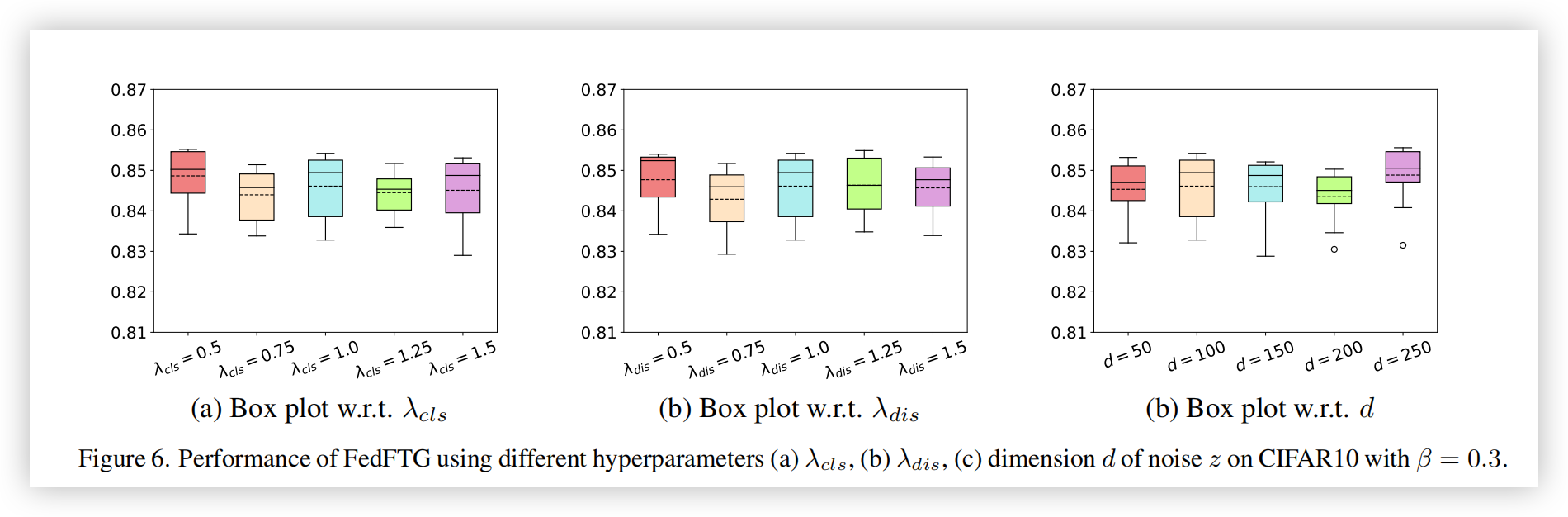
FedFTG 在超参数上的鲁棒性:为了衡量超参数选择的影响,我们从
关于特征级伪数据的讨论:FedGen 认为特征空间中的数据比输入空间更加紧凑,因此它在特征层生成伪数据,并对联邦模型的最后几层全连接层进行微调。受此启发,我们在表 5 中比较了使用特征级生成(F)和输入级生成(I)的 FedFTG 的性能。尽管 FedFTG(F) 的表现仍优于表 1 中的其他方法,但相比 FedFTG(I),性能有显著下降,这表明输入级生成对 FedFTG 更为有效。原因在于 FedFTG(F) 仅对全局模型的最后几层进行微调,导致知识迁移的效果有限。
 |  |
|---|
# 4.4 真实世界数据集上的实验
在本节中,我们测试了 FedFTG 在更具挑战性的真实世界数据集上的表现,包括车辆分类数据集 MIO-TCD [28] 和 CompCar [40],以及大规模图像分类数据集 Tiny-ImageNet。为了更好地验证 FedFTG 的有效性,我们使用了 CompCar 的监控子集,该子集的图像来自监控摄像头。对于 MIO-TCD 和 Tiny-ImageNet,我们将训练数据分配给 100 个客户端,而对于 CompCar,客户端数量为 50。所有数据集的 Dirichlet 分布
从表中可以看出,FedFTG 在所有场景中均优于其他方法,验证了其在真实世界联邦学习应用中的有效性。FedDF 和 FedGen 也采用了无数据知识生成来提升联邦模型性能。虽然它们的表现优于 FedAvg 和 FedProx,但 FedFTG 的表现领先它们 1% 到 6%,进一步验证了 FedFTG 提出的模块的有效性。
# 5. 讨论
隐私问题:由于 FedFTG 在服务器中恢复了客户端的训练数据,这可能会违反联邦学习中的隐私规定。然而,根据我们的观察,伪数据只捕捉到了真实数据的高层特征模式,这些模式人类无法理解(见图 2)。此外,由于生成器是由所有本地模型共同训练的,伪数据往往展示的是客户端数据的共享特征,这意味着个体数据的属性不会被泄露。上传客户端数据的标签统计信息也可能会泄露隐私。一个可选的解决方案是在标签统计信息中加入噪声。根据我们的实验,当噪声比例小于 10% 时,其对性能的影响在 CIFAR10 数据集
通信成本:与其他方法相比,FedFTG 只需额外传输训练数据的标签统计信息(即
局限性:该工作的主要局限性在于计算效率。由于 FedFTG 除了本地训练外,还需要额外训练全局模型,这使得整个训练时间比其他方法更长。在我们的实验中,FedFTG 每轮通信所需时间大约是 FedAvg 的两倍。此外,由于全局模型的训练是在服务器上进行的,FedFTG 更适用于[17]中定义的跨边缘(cross-silo)联邦学习应用,即服务器是拥有充足计算资源的组织。
# 6. 结论
本文提出了一种新的无数据知识蒸馏方法——FedFTG,用于微调全局模型并提升联邦学习的性能。我们提出了一种难样本挖掘方案,以有效挖掘本地模型中的知识并将其传输到全局模型中。在面对数据异质性场景中的标签分布偏移问题时,我们提出了定制化标签采样和类别级集成,最大化地利用知识。在五个基准上的大量实验验证了所提出的 FedFTG 的有效性。
# 致谢
本工作得到了中国国家自然科学基金项目 62088102 的支持,部分由吴德芳慈善基金会捐赠赞助的 PKU-NTU 联合研究院(JRI)支持,以及部分由科技创新 2030——“脑科学与类脑研究”重大项目(编号 2021ZD0201402 和 2021ZD0201405)支持。