 FedMD & Heterogenous Federated Learning via Model Distillation
FedMD & Heterogenous Federated Learning via Model Distillation
# FedMD: Heterogenous Federated Learning via Model Distillation
提示
该论文使用迁移学习和知识蒸馏开发了一个通用框架,允许在每个参与者不仅拥有自己的私有数据,还拥有独立设计模型的情况下进行联邦学习。
原论文地址:https://arxiv.org/abs/1910.03581
# 摘要
联邦学习使得在不损害多个参与者数据隐私的情况下构建强大的集中模型成为可能。尽管取得了成功,但它并未涵盖每个参与者独立设计其模型的情况。由于知识产权问题以及任务和数据的异质性,这在联邦学习应用于医疗保健和AI即服务等领域时是一项普遍需求。在这项工作中,我们使用迁移学习和知识蒸馏开发了一个通用框架,允许在每个参与者不仅拥有自己的私有数据,还拥有独立设计模型的情况下进行联邦学习。我们在MNIST/FEMNIST和CIFAR10/CIFAR100数据集上测试了我们的框架,并观察到所有参与模型的快速改进。对于10个不同的参与者,每个模型的最终测试准确率平均比没有协作时提高了20%,并且仅比将所有私有数据集汇集并直接供所有参与者使用时的性能低几个百分点。
# 1. 引言
深度学习提供了一个潜力巨大的框架,能够自动化感知和推理。然而,想要完全实现这一潜力需要大量数据。在像医疗这样的领域,收集大规模数据集往往是困难且昂贵的。例如,美国的典型医院可能仅拥有几十张特定疾病的MRI图像,这些图像需要由人工专家标注,还必须受到隐私泄露的保护。联邦学习及类似的概念【1, 2】应对此挑战,能够有效训练一个集中模型,同时将用户的敏感数据保留在设备上。特别是,联邦学习【1, 3, 4】针对更快的通信进行了优化,并且在处理大量用户方面具有独特的能力。
联邦学习面临着许多挑战【5】,其中一个特别重要的挑战是学习过程中的异质性问题。系统异质性体现在每个参与者拥有不同的带宽和计算能力;这种问题在联邦学习的原生异步方案中得到部分解决,后续的改进如主动采样【6, 7】和提高容错性【8】进一步完善了这一点。此外,统计异质性(非独立同分布问题)则表现为客户端拥有来自不同分布的不同数量的数据【9, 10, 11, 12, 13, 14】。
在本工作中,我们关注另一种类型的异质性:本地模型的差异性。在最初的联邦学习框架中,所有用户必须就一个集中模型的特定架构达成一致。这在参与者是数百万低容量设备(如手机)的情况下是合理的假设。而我们则探索了在面向企业场景的联邦框架扩展中,每个参与者有能力并希望设计其独特模型的现实情况。这种情况在医疗、金融、供应链和AI服务等领域中经常出现。例如,当多个医疗机构在不共享私有数据的情况下合作时,它们可能需要根据不同的需求设计自己的模型。出于隐私和知识产权的考虑,它们可能不愿共享模型的细节。另一个例子是AI即服务。一个典型的AI供应商(如客户服务聊天机器人)的客户可能有几十家公司。每个客户的模型都是独特的,并解决不同的任务。通常的做法是仅使用每个客户自己的数据来训练模型。如果能在不损害隐私和独立性的前提下利用其他客户的数据,这将非常有益。如何在每个参与者都拥有对其他人是“黑箱”的不同模型的情况下进行联邦学习?这是我们将在本文中回答的核心问题。
这一问题与联邦学习的非独立同分布挑战密切相关,因为应对统计异质性的自然方法是为每个用户定制个性化的模型。事实上,现有的框架已经导致了略微不同的模型。例如,文献【10】提供了一个多任务学习的框架,如果问题是凸的。基于贝叶斯【11】、元学习【12】和迁移学习【14】等框架的方法在处理非独立同分布数据时表现良好,并允许一定程度的模型定制。然而,据我们所知,现有的所有框架都要求对本地模型的设计进行集中控制。模型完全独立性虽然与非独立同分布问题相关,但作为一个新的研究方向有其独特的重要性。
实现模型完全异质性的关键在于通信。特别是,必须有一个翻译协议,使深度网络能够在不共享数据或模型架构的情况下理解其他网络的知识。这个问题触及了深度学习中的一些基本问题,如可解释性和新兴的通信协议。原则上,机器应该能够学习适应任何特定用例的最佳通信协议。作为朝这个方向迈出的第一步,我们采用了一个更为透明的基于知识蒸馏的框架,来解决这一问题。
迁移学习是解决私有数据稀缺问题的另一个重要框架。在本工作中,我们的私有数据集可能每个类别只有少量样本。因此,除了联邦学习之外,使用大规模公共数据集的迁移学习是必不可少的。我们通过两种方式利用迁移学习的力量。首先,在进入协作之前,每个模型首先在公共数据上进行完整训练,然后再在私有数据上进行训练。其次,更重要的是,这些黑箱模型通过它们在公共数据集上的输出分类得分进行通信。这是通过知识蒸馏【15】实现的,知识蒸馏能够以一种与模型无关的方式传递已学习的信息。
贡献:本工作的主要贡献是提出了FedMD,一个新的联邦学习框架,允许参与者独立设计其模型。我们的集中服务器不控制这些模型的架构,只需有限的黑箱访问权限。我们识别出该框架的关键元素是一个通信模块,用于在参与者之间传递知识。我们通过利用迁移学习和知识蒸馏的力量实现了这一通信协议。我们使用FEMNIST数据集【16】和CIFAR10/CIFAR100数据集【17】的子集测试了该框架,发现使用该框架的本地模型性能相比于没有协作时有显著提升。
# 2 方法
我们提出如下挑战:
# 2.1 问题定义
在联邦学习过程中,有 m 个参与者。每个参与者拥有一个非常小的标注数据集
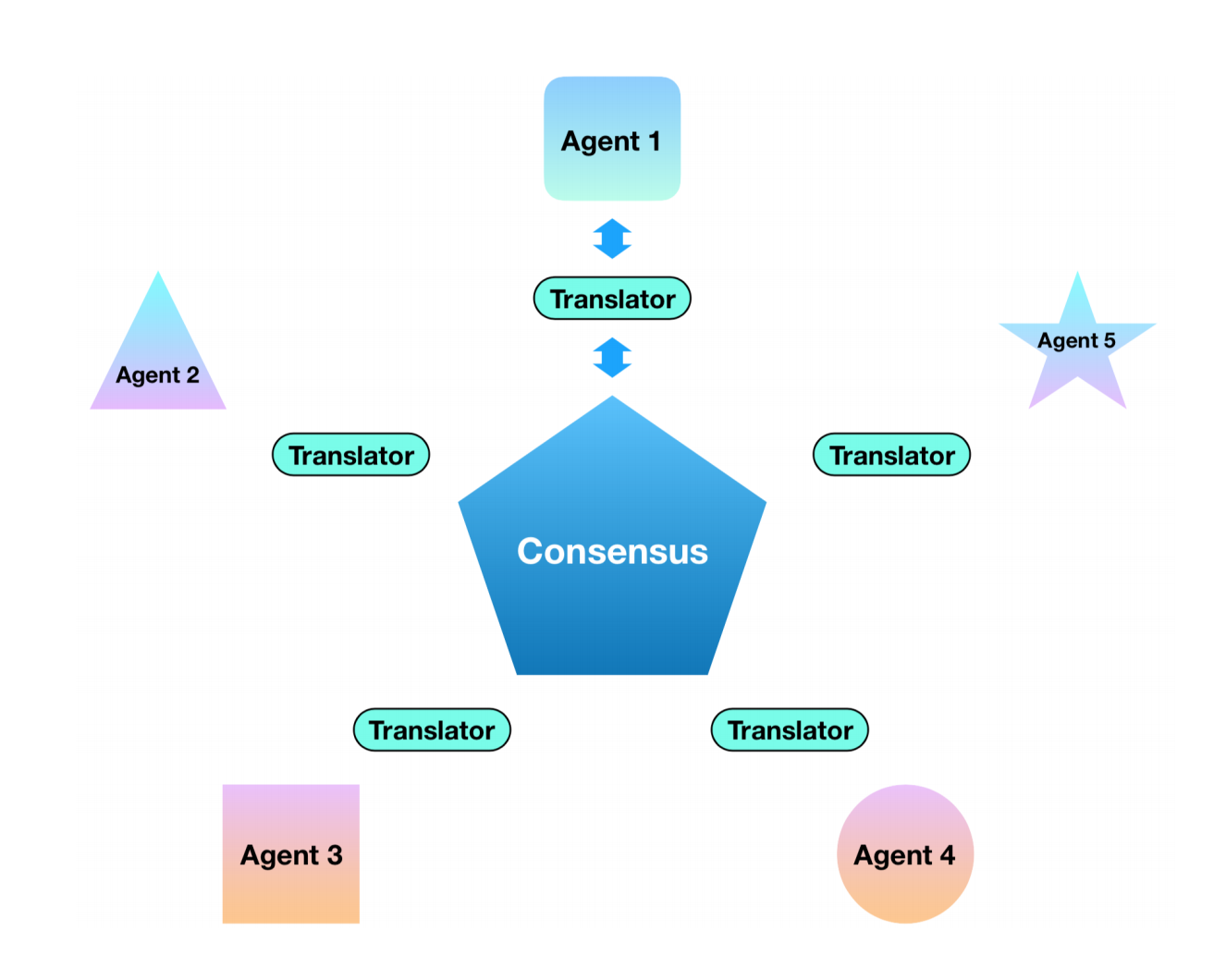
图1:一个用于异构联邦学习的通用框架。每个参与者拥有一个私有数据集和一个独特设计的模型。为了在不泄露数据的情况下进行沟通与协作,参与者需要将所学的知识转换为标准格式。一个中央服务器收集这些知识,并计算一个分布于网络的共识。在本工作中,知识翻译器通过知识蒸馏实现。
# 2.2 异构联邦学习框架
我们提出了FedMD(算法1),该框架解决了2.1节中定义的问题。我们在此对该框架的关键组件进行讨论。
这里的“得分”(score)指的是每个参与者模型在公共数据集上的Logit也可以是输出分类概率,作者认为不会有很大影响,也就是模型对每个样本所属类别的预测值。
算法1:FedMD框架使异构模型可以进行联邦学习。
输入:公共数据集
输出:训练好的模型
- 迁移学习:每个参与者在公共数据集
上将模型 训练至收敛,然后在私有数据集 上训练。 - 迭代执行
: - 沟通:每个参与者在公共数据集上计算分类得分
,并将结果传输至中央服务器。 - 聚合:服务器计算更新后的共识,即得分的平均值:
- 分发:每个参与者下载更新后的共识
。 - 消化:每个参与者在公共数据集
上训练其模型 以逼近共识 。 - 回顾:每个参与者在其私有数据集
上再训练模型若干个周期。
- 沟通:每个参与者在公共数据集上计算分类得分
迁移学习:在参与者进入协作阶段之前,其模型必须首先经历完整的迁移学习过程。模型将先在公共数据集上完全训练,然后在私有数据集上训练。因此,任何未来的改进都是与此基线进行比较。
通信:我们重新利用公共数据集
# 3 结果
我们在两种不同的环境下测试了这一框架。在第一个环境中,公共数据集是MNIST,私有数据集是FEMNIST的一个子集。我们考虑了i.i.d.(独立同分布)情况,其中每个私有数据集是从FEMNIST中随机抽取的;以及non-i.i.d.(非独立同分布)情况,其中每个参与者在训练期间只接收来自某一书写者的字母,但在测试时需要分类所有书写者的字母。
在第二个环境中,公共数据集是CIFAR10,私有数据集是CIFAR100的一个子集,CIFAR100包含100个子类,分属于20个超级类(如熊、豹、狮子、老虎和狼都属于大型食肉动物超级类)。在i.i.d.情况下,任务是要求每个参与者对测试图像进行正确的子类分类。non-i.i.d.情况则更具挑战性:在训练期间,每个参与者只能接触每个超级类中的一个子类的数据;但在测试时,参与者需要将泛化的测试数据分类到正确的超级类中。例如,一个训练期间只见过狼的参与者在测试时需要正确地将狮子分类为大型食肉动物。因此,他们需要依赖其他参与者传递的信息。
在每个环境中,10名参与者设计了不同的卷积网络,这些网络在通道数和层数上有所不同,详细信息见表1和表2。首先,它们在公共数据集上进行训练直到收敛——这些模型在MNIST上的测试准确率通常约为99%,在CIFAR10上的准确率约为76%。接下来,每个参与者在其自己的小型私有数据集上训练模型。经过这些步骤后,它们进入协作训练阶段,在此期间,模型全方位地迅速获得强劲的性能提升,并很快超过了迁移学习的基准。我们使用Adam优化器,初始学习率为0.001;在每轮协作训练中,我们随机选择大小为5000的公共数据集子集
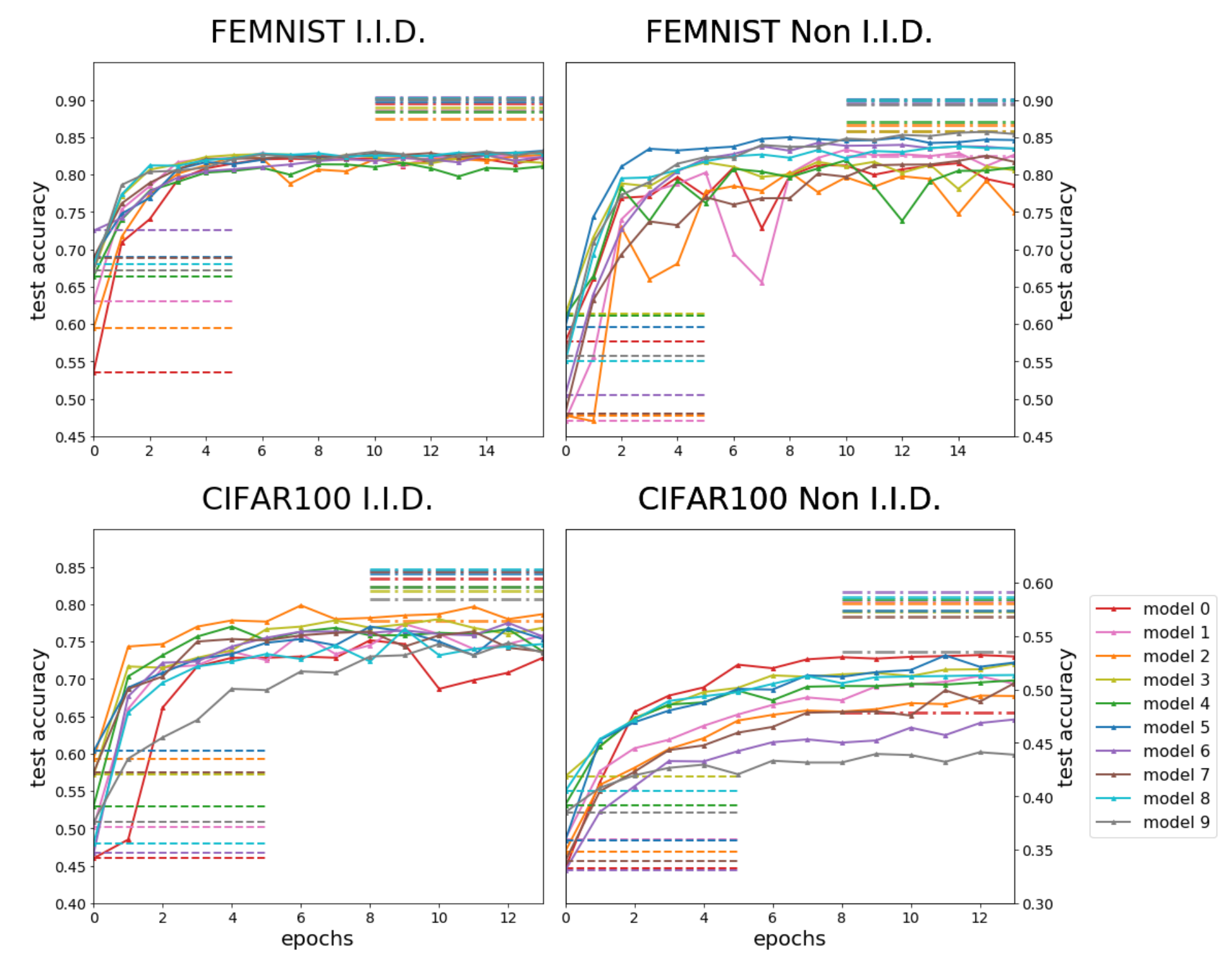
图2:FedMD提升了参与模型的测试准确率,超过了它们的基准表现。虚线(左侧)表示模型在使用公共数据集和它自己的小型私有数据集进行完全迁移学习后的测试准确率。这个基准是我们的起点,并与相应学习曲线的起始点重叠。点划线(右侧)表示如果所有参与者的私有数据集被解密并向每个参与者公开时模型的假想表现。
# 4.讨论和总结
在这项工作中,我们提出了FedMD,一个允许独立设计模型进行联邦学习的框架。我们的框架基于知识蒸馏,并已在各种任务和数据集上进行了测试验证。在未来,我们将探索更复杂的通信模块,例如特征变换和新兴的通信协议,以进一步提升我们框架的性能。我们的框架也可以应用于自然语言处理(NLP)和强化学习相关的任务。我们还将把框架扩展到极端异质性场景,涉及数据量、模型容量和本地任务之间的巨大差异。我们相信,异质联邦学习将在未来深度学习的广泛商业应用中成为重要工具。
方法
我们澄清一下关于算法1实现的一些重要细节:
在通信阶段,模型在对公共数据计算出的logits进行通信和对齐时,并未应用softmax激活层。我们也可以使用带有特定温度的softmax得分 [15],但我们认为这一区别不会带来较大影响。
在通信阶段,我们并未使用整个公共数据集,而是每轮随机选取大小为5000的子集。这加快了处理速度,而不影响性能。
消化阶段和回顾阶段的轮次数和批量大小控制了学习过程的稳定性。模型的测试性能可能会出现暂时的倒退,但在接下来的几轮中迅速恢复。这个问题可以通过在回顾阶段选择较少的轮次数和在消化阶段选择较大的批量大小来解决。
原则上,模型共识可以通过加权平均来计算:
在我们的工作中,我们几乎总是选择权重
等于 。唯一的例外是在CIFAR数据集上,我们对两个较弱的模型(0和9)的贡献进行了轻微的抑制。当我们有极为不同的模型或数据时,这些权重可能变得更加重要。
结果
我们讨论了结果中的几个有趣方面:
- 我们的结果是基于模型在所有参与者的私有数据汇集并直接向整个群体开放时,可能达到的测试精度进行衡量的。见表4。通常,我们的框架将所有参与者的性能提升到比汇集数据性能低仅几个百分点的水平。
- 在个别情况下,使用我们框架训练的模型持续优于在汇集私有数据中训练的相同模型,特别是在CIFAR非独立同分布(non-i.i.d.)的情况下的模型0。此外,它的性能通常处于群体的前列。这个模型的架构最为简单,通常落后于那些更复杂的模型。理解这种成功的机制并利用它来改进我们的框架是很有趣的。
- 我们的框架可以应对极端的模型异构性。我们曾尝试使用性能低得多的模型,例如两层全连接网络。如果它们与高级模型以相同的权重参与共识,它们往往会拖累群体的精度。我们的框架在降低它们的权重时表现更好。
# 5.致谢
我们感谢Ethan Dyer、Jared Kaplan、Jaehoon Lee、Patrick (Langechuan) Liu、Sam McCandlish、Wenbo Shi、Gennady Voronov、Yunlong Wang、Sho Yaida、Xi Yin 和 Yao Zhao 对这篇手稿的讨论和意见。DL得到了西蒙斯合作项目“非微扰自举”的资助。