 机器学习中的并行计算
机器学习中的并行计算
# 机器学习与并行计算
# 1.为什么机器学习需要并行计算?
机器学习的发展离不开并行计算的支持。随着模型规模和数据集大小的增长,计算需求也在增加。传统的串行计算方法已经无法满足机器学习模型的训练需求,导致训练时间过长、计算资源浪费。并行计算技术可以将计算工作负载分布到多个处理器或节点上,实现高速计算和加速模型训练。通过并行计算,我们可以更快地训练机器学习模型,提高模型的准确性和泛化能力,推动机器学习技术的发展和应用。
# 2.原理上解释为什么可以实现并行结算
# 2.1 回顾最小二乘回归
在机器学习中,我们经常遇到基于一组输入特征预测连续输出变量的问题。其中最广泛使用的算法之一是最小二乘回归。
问题公式
输入:
(例如房屋特征)。 预测:
(例如房屋价格)。 问题: 如何找到
?
训练数据
训练输入:
。 训练目标:
。
损失函数
损失函数:
。 目标: 找到使损失函数最小的
,即 。
# 2.2 梯度下降
为了最小化损失函数我们需要求梯度:
这个公式表明梯度可以并行计算,因为每个项
以下是AI写的有待考证
对于特征并行,我们可以将向量
由于
这里的每一项
可以独立计算。
这样的分解显示了如何将特征并行化处理。每个
通过这种方式,可以在不同的处理单元上并行计算每个特征部分的梯度贡献,最终通过合适的同步机制合并这些结果。这种方法尤其在特征维度很高,且模型分布在多个处理单元上时非常有效。
# 2.3 并行化
通过计算每个样本的梯度项
eg:2个cpu并行计算梯度

# 2.4 梯度下降更新规则
梯度下降更新规则是一个迭代过程,用于更新模型参数
其中:
是当前估计的模型参数在迭代 的值 是学习率,控制每次更新的步长 是损失函数的梯度,在当前估计的模型参数 处计算
该规则的意思是,我们从当前估计的模型参数
# 3.并行梯度下降中的通信问题
当我们尝试并行化梯度下降算法时,一个最大的挑战是处理器之间的通信。在并行梯度下降算法中,每个处理器负责计算梯度的一部分,然后将每个处理器的梯度聚合以获取最终的梯度。
# 3.1 share Memory
在共享内存并行计算中,多个处理器或核心共享一个公共内存空间。
优点:
- 处理器之间快速访问和交换数据,因为它们可以直接访问共享内存。
- 易于实现和编程,因为共享内存模型通常对开发者来说是熟悉的。
- 适合小型到中型并行应用程序,其中共享内存可以被高效地管理。
缺点:
- 大规模上不去,一台机器是有瓶颈的,一个机器上最顶配也不行对于大模型。
# 3.2 Message Passing
在每台机器或节点都是独立的设备,数据通过消息在机器之间传递。有两种方式:Client-Server和P2P两种架构
优点:
- 可扩展到大量处理器和节点
- 灵活适应不同并行算法和应用程序
- 适合分布式内存架构和集群
缺点:
- 由于消息传递而导致的延迟和开销增加
- 实现和编程更加复杂
# 4.并行梯度下降的几种方式
# 4.1 同步算法MapReduce
MapReduce 是 Google 开发的一种编程模型和软件系统 ,不开源,是一种批量同步并行算法。它基于Client-Server架构,使用消息传递通信,并采用批量同步并行处理。客户端将作业提交到 MapReduce 集群,该集群由多个节点组成。每个节点运行 MapReduce 守护进程,负责执行 Map 和 Reduce 任务。MapReduce 适合大数据处理,并不适用于机器学习。
MapReduce 算法
MapReduce 算法用于并行梯度下降包括以下步骤:
- Map 阶段:输入数据被分割成小块,并分布到多个 Map 节点。每个 Map 节点计算其数据块的损失函数梯度。
- Shuffle 阶段:Map 节点的输出被分区并分布到多个 Reduce 节点。
- Reduce 阶段:每个 Reduce 节点计算更新的模型参数,通过聚合 Map 节点的梯度(求和,求平均,计数等)。
在每个阶段,所有任务都是同步执行的,直到所有任务完成后,才会进入下一个阶段。这意味着 MapReduce 算法是同步的,它需要等待所有任务完成后,才能继续执行下一个阶段。
开源实现
Apache Hadoop [2] (java写的)是 MapReduce 的开源实现,提供了可扩展和灵活的框架并行处理。Apache Spark [3] 是 MapReduce 的改进开源实现,提供了更高的性能和更多的高级功能。
优点
MapReduce 基于并行梯度下降算法具有以下优点:
- 可扩展性:算法可以处理大型数据集,通过分布式计算跨多个节点。
- 灵活性:算法可以与不同的梯度下降算法和模型架构一起使用。
- 高性能:算法可以通过 MapReduce 集群的并行处理能力实现高性能。
缺点
MapReduce 基于并行梯度下降算法也具有以下缺点:
- 通信代价:节点越多通信越高,参数多可能很大大模型
- 网络延迟:网络带宽,网络问题
- 节点的计算能力不同:可能会等待其他节点同步,节点挂掉等
# 4.2.异步算法 Paramter-Server
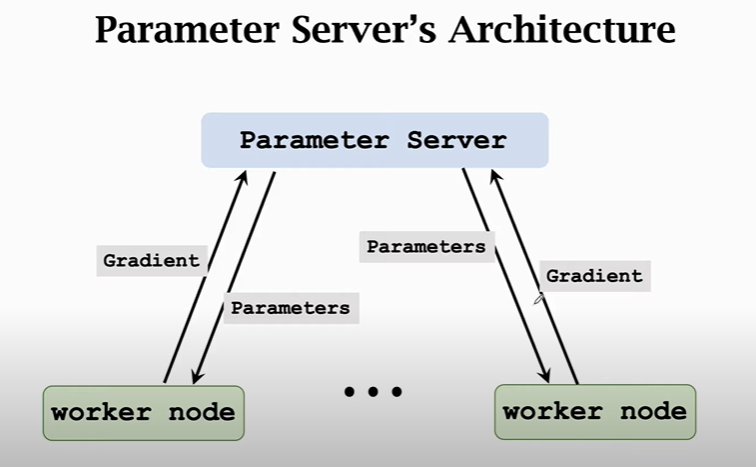
这个看起来和MapReduce没什么区别都是Client-Server架构,最主要的区别是这个是异步的。如果想用这种模式做机器学习实验可采用Ray。Ray 是一个开源系统,用于构建可扩展和容错的分布式应用程序,它由加州大学伯克利分校的 Ray 团队开发,现在由 Linux 基金会维护。
优点:
- 更快收敛:异步并行梯度下降可以比同步梯度下降更快收敛,尤其是在大规模数据集上。
- 系统利用率更高:计算节点无需等待其他计算节点
- 容错性:异步并行梯度下降可以容忍单个机器或节点的故障,并且可以继续收敛,即使一些机器故障。
缺点:
- 要求计算设备能力基本一致,文档:这里也是限制联邦学习为什么不能使用异步(场景中例如手机设备不稳定),由于部分work计算太慢,收敛会出问题会拿之前的梯度更新最新模型参数
# 5.分布式计算和并行计算区别
当我们探讨并行计算(Parallel Computing)与分布式计算(Distributed Computing)时,虽然这两者在某种程度上是相关联的,但它们之间还是存在明显的区别。这些区别没有绝对的界限,并且在学术界也没有统一的共识。不同领域的专家可能会有不同的观点。
高性能计算(HPC)领域的观点:
- 在高性能计算领域,当计算节点不处于同一物理位置时,通常会将并行计算称为分布式计算。这种情况下,计算任务被分配到地理位置分散的多个计算节点上,每个节点都可能有自己的内存和处理器,节点间通过网络相互通信。
机器学习(ML)领域的观点:
- 在机器学习领域,当数据或模型在多个节点之间分割时,此时的并行计算被称为分布式计算。这种设置使得大型数据集或复杂模型可以在多个计算资源上同时处理,加快了计算速度并能处理更大规模的数据。
对比单节点多处理器的情况:
- 当计算完全在一个单独的节点内进行,而该节点拥有多个处理器(或多核处理器)时,这种情况通常不被称为分布式计算。尽管这也是一种并行计算形式,因为任务可以在同一节点的不同处理器之间并行处理,但所有的计算资源都位于单一物理位置,共享同一内存系统。
总结来说,分布式计算强调的是计算任务在物理上分散的多个计算节点间的分布,这些节点通过网络连接,共同完成计算任务。而并行计算则更注重在多个处理器之间并行执行计算任务,不论这些处理器是位于一个节点还是多个节点。这种区分在于计算资源的分布和任务执行的方式上。