 Knowledge Distillation in Federated Learning:A Practical Guide
Knowledge Distillation in Federated Learning:A Practical Guide
# 综述论文“Knowledge Distillation in Federated Learning: A Practical Guide”分享
Alessio Mora¹, Irene Tenison², Paolo Bellavista¹, Irina Rish³
¹ 博洛尼亚大学
² 麻省理工学院 (MIT)
³ Mila,蒙特利尔大学
alessio.mora@unibo.it, itenison@mit.edu, paolo.bellavista@unibo.it, irina.rish@mila.quebec
# 摘要
联邦学习(Federated Learning, FL)允许在不集中收集潜在敏感的原始数据的情况下,协同训练深度学习模型。目前最常用的联邦学习算法是基于参数平均的方案(例如联邦平均算法,Federated Averaging, FedAvg),但这些方法存在已知局限性,例如模型同质性要求、高通信成本,以及在数据分布非独立同分布(Non-IID)条件下表现不佳的问题。基于知识蒸馏(Knowledge Distillation, KD)的联邦学习方法可以解决或缓解参数平均算法的这些缺点,但也可能引入新的性能权衡。在本文中,我们针对联邦学习环境中基于知识蒸馏的算法进行了全面综述,提出了现有方法的新颖分类,并详细分析了这些方法的优点、局限性及其在联邦学习场景下的适用权衡点。
原论文地址:https://www.ijcai.org/proceedings/2024/905
# 1 引言
联邦学习(Federated Learning, FL)被提出作为基于云的深度学习(Deep Learning, DL)的替代方案。这一范式将深度学习模型的训练能力与收集原始数据的需求解耦开来,通过设备端计算与周期性通信交替进行【McMahan 等, 2016; Bellavista 等, 2021】。在学习过程中,参与者仅需共享临时且本地处理的载荷(payload),这使得推断个体的隐私信息变得更加困难。
联邦平均算法(Federated Averaging, FedAvg)是联邦学习的基线算法【McMahan 等, 2016】。在FedAvg中,协作学习通过客户端-服务器范式以同步轮次(synchronous rounds)进行。参与者(即客户端)通过迭代的方式与中央聚合器(即服务器)交换模型更新和模型权重,共同构建全局模型。服务器在每轮中以加权平均的方式聚合模型更新,并分发全局模型的新版本。
然而,基于参数平均的聚合方案,如FedAvg,存在众所周知的局限性:
- 模型同质性要求:这类算法要求联邦内所有客户端使用相同的神经网络架构,因为服务器需要直接合并客户端的更新(例如通过加权平均)。当联邦内的客户端具有异构硬件能力时,这可能成为问题。
- 高通信成本:模型参数和模型更新的交换通信成本与模型参数的数量成正比。尽管已有许多策略(如【Sattler 等, 2019】)提出通过降低通信效率来改善全局模型性能,但总体通信成本依然显著。
- 信息泄漏与知识产权问题:交换模型参数/更新会暴露客户端的信息。此外,服务器需要了解客户端模型的架构和结构才能广播全局参数,这可能导致知识产权问题(例如,联邦内的客户端可能不愿共享其使用的模型架构)。
- 客户端漂移:当客户端持有异构数据时,局部模型在训练过程中倾向于基于私有样本进行微调,导致模型间的差异加大(即客户端漂移,client drift)。因此,直接聚合模型参数/更新会降低全局模型的性能【Karimireddy 等, 2020】。
本文重点回顾了针对联邦学习环境中基于知识蒸馏(Knowledge Distillation, KD)的技术改编,以缓解上述参数平均聚合方案的不足。最初,基于隐私特性的驱动【Papernot 等, 2016】,KD策略被引入以支持模型异构性,并通过交换模型输出和/或与模型无关的中间表示代替直接传输模型参数/更新,从而降低通信成本。随后,一些策略通过在服务器端加入集成蒸馏阶段增强FedAvg的聚合过程,以支持模型异构性和/或在异构数据下改进模型融合。近期,两类基于KD的工作聚焦于缓解客户端模型漂移现象,这种现象降低了基于平均的聚合效率。一类工作通过在客户端目标函数中加入正则化项,另一类工作利用全局学习的无数据生成器(data-free generator)来解决该问题。
据我们所知,这是首篇系统分类并讨论基于KD的方法在联邦学习中解决特定问题的论文。本文的主要贡献如下:
- 提出了基于KD的联邦学习方法的新颖分类法:帮助研究者更好地理解蒸馏启发方法的潜力及其进一步应用。
- 详细技术综述:对现有KD方法的核心目标、设计/实现选择的动机进行了详细技术分析,并讨论了它们的优点及可能的缺点。
- 探讨了KD在该领域的新兴应用:重点展示了未来研究的潜在方向。
本文的结构如下:
第2节介绍了知识蒸馏的基础。
第3节讨论了使用KD实现模型异构性的联邦学习算法。
第4节描述了使用KD缓解数据异构性对全局模型性能影响的联邦学习算法。
最后,第5节简要探讨了KD在联邦学习中解决其他相关问题的新兴应用。
# 2 背景
# 2.1 知识蒸馏
知识蒸馏(Knowledge Distillation, KD)方法旨在将知识从较大的深度神经网络(即教师网络)传递到较小的轻量级网络(即学生网络)【Hinton 等, 2015】。在最简单的 KD 形式中,学生模型通过模仿(预训练)教师模型在代理数据集(亦称传输集)上的输出进行学习。如果传输集是有标签的,学生可以通过以下两种损失函数的线性组合进行训练:
其中,
# 2.2 协同蒸馏
协同蒸馏(Codistillation, CD)是一种在线版本的蒸馏方法,它无需常规 KD 中的预训练教师网络【Anil 等, 2018; Gou 等, 2021】。实际上,CD 同时训练模型的

图 1:解决联邦学习问题的基于 KD 方法的分类。
# 2.3 提出的分类和定义
图 1 展示了我们对 KD 机制的分类,这些机制旨在实现模型异构性或缓解数据异构性的影响。表 1 列出了本文综述中最相关的研究工作,并根据其主要目标对解决方案进行了分类。对于每种解决方案,我们详细说明了每轮交换信息的类型、辅助数据的需求以及所涉及的 KD 类型。其中,基于正则化的方法使用 KD 对本地训练进行正则化;基于生成器的机制利用生成器模型组装合成数据,并将知识作为归纳偏置进行传递;消化意味着通过模仿教师对相同代理数据的输出来吸收知识

表 1 展示了所调查解决方案的概览。我们为主要目的识别了六个可能的类别:模型异质性(MH)、非独立同分布(NIID)、通信效率(CE)、反向学习(FU)、个性化(P)以及类别增量学习(CI)。上传(Upload)指的是客户端到服务器的通信链路。符号说明包括:
# 3 基于知识蒸馏实现联邦学习的模型异构性
知识蒸馏(KD)最初设计用于在结构和深度不同的神经网络之间传递知识。在本节中,我们回顾了采用 KD 实现联邦学习(FL)中模型无关性的方法,即在具有异构模型架构的客户端之间传递知识。
# 3.1 增强 FedAvg 聚合
FedAvg 协议可以通过在聚合步骤中结合服务器端的集成蒸馏来增强,以支持模型异构性【Lin 等, 2020; Sattler 等, 2021a】。通过这种方法,可以在具有不同模型架构的客户端之间传递知识。
具体来说,服务器可以维护一组原型模型,每个原型模型代表所有具有相同架构的学习者。在从客户端收集更新后,服务器首先针对每个原型模型执行聚合,然后通过使用无标签数据或合成生成的样本为每个接收到的客户端模型生成软目标(soft targets)。接着,将这些软目标进行平均,并用于微调每个聚合后的模型原型。
另一种可能的实现模型异构性的解决方案是利用协同蒸馏(CD)的分布式变体,而非参数平均算法(如 FedAvg)。这些方法将在后续内容中介绍。
# 3.2 协同蒸馏的联邦学习适配
在协同蒸馏(CD)的通用联邦学习适配中【Anil 等, 2018】,每一轮
因此,在分类任务中,CD 的联邦学习适配通过交换不同类型的知识避免了上述依赖于公共训练数据样本的模型响应收集问题。文献中的解决方案中,识别出以下三种类型的知识可用于实现 CD 的联邦版本:
- 模型响应在本地数据上的统计量的集合(例如,每类标签的平均模型响应)。
- 模型响应在公开可用数据集(而非本地数据)上的集合。
- 模型响应与与模型无关的中间特征的集合。
值得注意的是,客户端和服务器交换的是这些类型的信息,而非模型参数。此外,CD 的 FL 适配放宽了需要实现相同模型架构的限制,这一限制在面向数据中心的分布式训练中的常规 CD 中是必要的。实际上,基于模型响应(或与模型无关的中间特征)交换知识可以使工作者(即 FL 客户端)之间的模型实现异构化,只要它们具有相同的输出形状。
图 2 展示了相对于 FedAvg 基线的 CD FL 适配。表 2 总结了以下子节中讨论的 CD FL 适配方案的对比。

表 2:通过 FL 调适的 CD 实现模型异质性的策略比较。
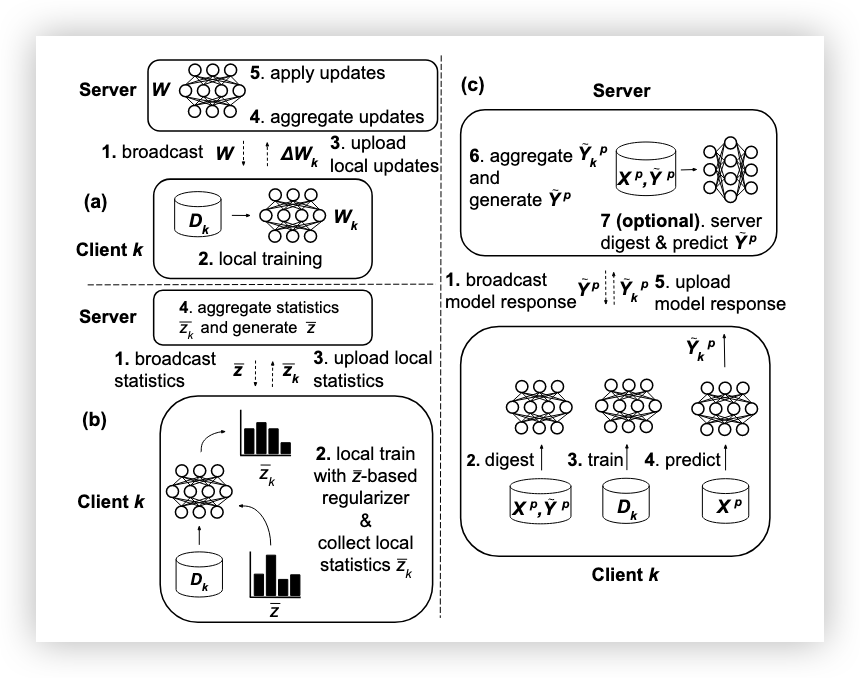
图 2:基于 KD 的联邦学习解决方案。 (a) FedAvg,(b) 基于统计的联邦知识蒸馏,(c) 基于响应的联邦知识蒸馏。
**披露本地数据模型响应的聚合统计量。**在 Jeong 等人【Jeong et al., 2018】提出的联邦学习(FL)蒸馏基线方法 FedDistill(如图 2b 所示)中,参与者周期性地传输仅基于其私有数据集计算的每类标签的平均软目标。服务器随后对这些张量进行平均,生成每类标签的全局软目标,并在下一轮广播给客户端。在本地训练时,客户端通过蒸馏项对本地损失进行正则化,该蒸馏项使用接收到的全局软目标作为教师模型的输出。类似的策略后来也在【Seo et al., 2020】中提出。
值得注意的是,对于分类任务中的深度学习模型,FedDistill 相较于基于参数的方案在通信效率上具有显著优势,因为通信的有效负载大小取决于模型响应的大小,而非模型的参数规模。
**交换在公开可用数据集上的模型响应。**联邦协同蒸馏(CD)可以通过使用代理转移数据集(公开可用,客户端和服务器都可以获取)的模型响应集合来实现。在这种方法中,客户端在私有数据上训练,并通过代理转移数据集上的模型响应共享知识。文献中的相关方法虽有不同,但一个通用的算法步骤框架可以概述如下(见图 2c):
- 广播:客户端接收当前的全局 logits 或软目标;
- 本地蒸馏:客户端在代理数据集的一个子集上模仿接收到的全局 logits 或软标签,从而蒸馏本地模型。这一步类似于传统协同蒸馏:每个客户端将上一轮其他客户端的平均预测视为虚拟教师。这一步也可以看作一种获取全局模型参数的方法,而不是像基于参数的方案(例如 FedAvg)那样直接从服务器接收参数;
- 重新训练(本地训练):客户端在本地数据上微调蒸馏后的模型;
- 本地预测:客户端在代理数据集的一个子集上计算本地 logits 或软目标;
- 上传:客户端上传计算得到的 logits 或软目标;
- 聚合:服务器聚合客户端的预测,生成更新后的全局 logits 或软目标;
- (可选)全局蒸馏:服务器在代理数据集的对应子集上使用聚合的软目标蒸馏模型,再次生成用于广播的全局 logits 或软目标。通过轮次更新服务器端模型,可以在客户端部分参与的情况下改善训练过程。随后新一轮开始。
表 2 总结了调查的文献工作相对于上述通用算法步骤的偏差情况。特别是,选择有标签或无标签的代理数据集会对算法设计产生影响。例如,FedMD【Li and Wang, 2019】在协议开始之前使用代理有标签数据集对客户端执行初步预训练阶段。Itahara 等人提出了一种熵减聚合(Entropy Reduction Aggregation, ERA)的方法,修改了聚合步骤,并证明了在将 softmax 应用于聚合 logits 时使用小于 1 的温度可以降低全局软目标的熵,从而有助于训练过程,特别是在非独立同分布(non-IID)的设置下【Itahara et al., 2021】。
压缩联邦蒸馏(CFD)【Sattler et al., 2021b】在客户端和服务器通信之前,针对软目标实施了一种基于量化和差分编码的极端且高效的压缩技术。Cronus【Chang et al., 2019】通过直接在私有数据集和软标签化的公共数据集的联合数据(即串联数据)上训练,将本地蒸馏和重新训练步骤合并。此外,Cronus 在软目标的聚合上采用了【Diakonikolas et al., 2017】中提出的增强鲁棒性的方法。类似于 Cronus,MATH【Hu et al., 2021】让客户端联合在私有数据集、公共数据集以及标注了全局软目标的公共数据集上训练。MATH【Hu et al., 2021】考虑了一个有标签的代理数据集,并通过在公共数据集及其软标签版本的联合数据上训练服务器模型来完成蒸馏。
FedGEM【Cheng et al., 2021】建议使用一个强大的服务器模型,其变体 FedGEMS 利用公共转移数据集中的标签来执行选择和加权策略,这种策略可以改进服务器端的蒸馏【Cheng et al., 2021】。
**利用中间特征。**FedAD【Gong et al., 2021】除了模型输出外,还使用中间特征来扩展基于响应的知识蒸馏。中间特征是与模型无关的注意力图【Selvaraju et al., 2017】,只要对注意力图的形状达成共识,这些特征仍然可以支持模型异构性。FedAD 是一种单轮次联邦学习框架,意味着客户端无需在每轮开始时蒸馏本地模型,并且可以异步参与训练。
FedGKT【He et al., 2020】结合了异步分布式学习范式【Poirot et al., 2019】和常规联邦学习,利用中间特征实现训练。边缘设备训练由特征提取器和分类器组成的小型网络,其中特征提取器生成中间特征图,分类器生成软目标。类似地,服务器使用一个更深的网络和分类器。在本地训练完成后,客户端会为每个本地样本传输计算得到的中间特征、预测的软目标以及相关的真实标签。服务器以客户端计算的中间特征为输入,通过其更深的网络生成全局软目标。客户端和服务器的目标函数是交叉熵损失和基于知识蒸馏的损失的线性组合:前者考虑软目标和真实标签,后者衡量本地和全局 logits 的差异。
类似的框架在 FedDKC【Wu et al., 2022b】中被实现并扩展,Wu 等人还开发了服务器端的知识优化策略。
# 3.3 比较与应用指南
联邦协同蒸馏(CD)的适配支持模型异构性,并可以在降低通信需求的同时增加相对于基于参数方案的计算开销。因此,尽管其通信效率极高,但由于客户端蒸馏带来的开销(如表 1 中提到的在客户端侧使用蒸馏的解决方案),这类算法可能无法部署到资源受限的设备上。然而,对于跨数据中心(cross-silo)场景,它是一种适合的模型无关替代方案。
此外,与 FedAvg 基线相比,这类解决方案通常在全局模型准确性方面表现不佳【Sattler et al., 2021a】,尽管它们通常提升了非协作训练的性能【Itahara et al., 2021】。
需要注意的是,这一类方法大多假定存在语义相似的代理数据集(有时甚至是带标签的),但在某些部署场景和使用案例(如特定的医疗应用)中,这可能是不现实的假设。
在【Jeong et al., 2018】中提出的通信高效且无数据的策略虽然不涉及本地计算开销,但其全局模型的测试准确性远低于 FedAvg【Zhu et al., 2021】,并且可能泄露与私有数据相关的敏感信息(如每类标签的模型输出)。
类似【He et al., 2020; Wu et al., 2022b】的解决方案支持模型异构性,通常比 FedAvg 更具通信效率,并通过采用分布式学习范式和基于知识蒸馏的正则化,使资源受限设备能够参与联邦学习。然而,正如表 1 所示,这些解决方案因其分布式学习方法披露了本地的真实标签,这可能导致隐私泄露。
# 4 通过知识蒸馏解决联邦学习数据异质性问题
基于知识蒸馏(KD)的解决方案可以用于提高在数据异质性存在时,全局模型的泛化性能。服务器端的方法通过在代理数据集上进行集成蒸馏或使用无数据生成器,来修正FedAvg的全局模型。另一方面,客户端机制通过在设备上使用正则化器或合成生成数据蒸馏全局知识,来限制本地过拟合或直接控制客户端漂移现象。
# 4.1 服务器端的全局模型精炼
在公开数据上的精炼。在[Lin et al., 2020]中,作者提出了FedDF,一种服务器端的集成蒸馏方法,用于同时实现模型异质性并增强FedAvg的聚合效果。在FedDF中,全局模型通过模仿客户端模型输出在代理数据集上的集成(例如,加权平均)来进行微调。FedAUX [Sattler et al., 2021a]通过在辅助数据上进行无监督预训练,增强了FedDF [Lin et al., 2020]的表现,找到了适合客户端特征提取器的模型初始化。此外,FedAUX根据每个参与者模型的(ε,δ)-差分隐私确定性得分对代理数据上的集成预测进行加权。[Chen and Chao, 2020]提出的FedBE通过贝叶斯模型集成结合客户端预测,以进一步提高聚合的鲁棒性。
无数据生成器。虽然服务器端的集成蒸馏方法假设存在代理数据集,但FedFTG [Zhang et al., 2022b]通过无数据知识蒸馏执行全局模型的服务器端精炼,其中服务器对生成器模型和全局模型进行对抗训练,并通过合成数据微调后者。另一种基于无数据生成器的全局模型精炼方法在[Zhang et al., 2022a]中提出。最近提出的DaFKD [Wang et al., 2023]同时利用服务器端和客户端生成器。在每轮FL中,服务器通过客户端模型的加权集成作为教师,精炼FedAvg聚合的全局模型。精炼后的全局模型使用以下形式的损失函数进行蒸馏:
其中,
# 4.2 客户端正则化
**本地正则化以减少过拟合。**在[Mendieta et al., 2022]中,Mendieta等人展示了GradAug [Yang et al., 2020],这是一种基于蒸馏的结构化正则化方法,虽然并非专门为联邦学习(FL)环境设计,但它能够有效地缓解客户端漂移问题,尽管会引入显著的计算开销。因此,Mendieta等人设计了一种新方法,FedAlign [Mendieta et al., 2022],其具有相似的效果和性能,但计算开销更加可持续。具体来说,FedAlign针对神经网络的较深层,这些层最容易因客户端分布不均而出现过拟合[Luo et al., 2021],并在本地目标函数中引入基于蒸馏的项。该项最小化全网络最后一层输出的中间特征与通过同一层但减少宽度(通过临时均匀修剪)得到的特征之间的差异。采用精简的子网络可以引入有限的计算开销。
**通过正则化项的本地-全局蒸馏。**受到微调优化思想和持续学习研究的启发,最近的研究[Yao et al., 2023;Ni et al., 2022]和[Lee et al., 2022]发现,本地基于知识蒸馏(KD)的正则化是减少联邦学习中非独立同分布(non-IID)数据影响的有效方法。在本地-全局蒸馏中,客户端的本地目标函数是交叉熵损失和基于KD的损失的线性组合:
其中,

图 3: 使用正则化项的本地-全局蒸馏。
**本地-全局蒸馏通过正则化项:进一步改进。**FedGKD [Yao et al., 2023] 使用一个由
**本地-全局蒸馏通过无数据生成模型。**与本小节中的其他工作不同,FedGen [Zhu et al., 2021] 学习了一个轻量级的服务器端生成器,该生成器逐轮分发给客户端,客户端利用该生成器获取增强的训练示例,并在本地学习中使用全局知识作为归纳偏置。
# 4.3 比较与采用指南
基于知识蒸馏(KD)的服务器端模型优化策略,如 [Lin et al., 2020; Sattler et al., 2021a; Chen and Chao, 2020],可以在高度异质的数据存在的情况下,通过使用语义相似的未标记代理数据来提高 FedAvg 全局模型的性能。值得注意的是,这类算法在多个本地训练轮次(local epochs)之间进行通信时效果最佳,特别是在客户端模型趋于偏离时。此外,这些算法不会在客户端引入额外的计算或通信开销。无数据生成模型也可以用于执行服务器端的全局模型修正,如 [Zhang et al., 2022b] 所示,或者像 [Zhu et al., 2021] 中那样,直接在参与的设备上限制客户端的漂移,这两种情况下都需要泄露本地标签计数。类似地,DaFKD [Wang et al., 2023] 通过生成器实现全局模型的无数据优化,但会在客户端引入计算和通信开销——尽管由于部分参数共享,开销是有限的。在通过利用全局模型输出对本地数据进行正则化的解决方案(如 FedGKD [Yao et al., 2023]、FedNTD [Lee et al., 2022]、FedLMD [Lu et al., 2023]、FedED [Guo et al., 2024])中,不需要从客户端披露额外的信息,甚至不需要代理数据。除此之外,这些策略不会在设备端引入显著的计算开销,并且与 FedAvg 具有相同的通信要求。然而,它们需要在内存中存储两个完整的模型(本地模型和作为参考的全局模型),但这一限制在实践中可以通过首先计算接收到的全局模型在本地数据上的预测,然后覆盖它继续进行本地训练来避免。如果有限的标记代理数据可用,可以通过类似 [He et al., 2022b; He et al., 2022a] 的方法改进本地-全局知识蒸馏。当适度或较大的计算开销可接受时,可以通过使用中间特征和混合路径来增强本地-全局蒸馏,如 FedMLB [Kim et al., 2022] 和 FedBR [Liu et al., 2023b] 所示,从而显著提高本地-全局蒸馏的效果。值得注意的是,在 FedMLB 和 FedBR 中,必须在训练过程中本地存储选定的全局模型块,而这不能像基于模型响应的正则化方法那样避免。如 [Kim et al., 2022] 所强调的,客户端侧的正则化可以与标准的服务器端策略结合使用,以提高性能(例如,FedOpt [Reddi et al., 2020])。
# 5. 知识蒸馏在联邦学习中的新兴应用
在此部分,我们概述了近年来知识蒸馏(KD)在解决其他联邦学习(FL)问题中的新兴应用,即个性化联邦学习、联邦遗忘和增量类别联邦学习。
KD在联邦学习个性化中的应用
个性化联邦学习的主要目标是构建一个能够迅速适应本地数据分布的全局模型。虽然基于知识蒸馏的解决方案通常用于增强全局模型的泛化能力(见第4节),最近,灵感来自蒸馏的机制被应用于个性化联邦学习算法。Jin等人提出了pFedSD,其中客户端存储其最后训练的个性化模型,并将其作为教师模型用于下一轮训练 [Jin et al., 2022]。简而言之,pFedSD使用图3所示的蒸馏框架,其中教师模型是过去的本地模型,而不是全局模型。此外,Chen等人最近提出了一种光谱蒸馏方法,用于通过一个最小化全局模型和个性化模型之间的KL散度的项来正则化本地训练 [Chen et al., 2023]。
KD在联邦遗忘中的应用
联邦学习客户端应具有请求从全局模型中删除其贡献的权利,针对客户端选择性遗忘的机制正在逐步出现。在 [Wu et al., 2022a] 中,解决方案首先从全局模型中删除遗忘客户端的历史模型更新。然后,服务器利用知识蒸馏快速恢复全局模型的性能,使得经过清洗的全局模型模仿最后一个全局模型在代理未标记数据上的输出。
KD在联邦增量学习中的应用
到目前为止,所调查的方法假设任务的分类类别在整个联邦学习过程中是固定的。相比之下,针对联邦环境下增量类别学习的研究逐渐涌现。在 [Liu et al., 2023a] 中,提出了FedET,该方法利用增强蒸馏方法来调整旧知识和新知识之间的不平衡。在 [Wu et al., 2024] 中,Wu等人设计了FedNASD,这是一种方法,利用当前模型的类别概率来近似历史模型对新类别的输出——历史模型可能包含较少的类别——因此,即使类别随着时间变化,仍然可以应用本地-全局蒸馏(见图3)。
# 6. 结论
知识蒸馏最近被嵌入到联邦学习算法中,以解决特定的联邦学习问题。在本综述中,我们展示了多种基于蒸馏的机制,这些机制主要是为了实现模型异质性,并应对联邦学习中数据异质性的影响,在某些情况下,还可以减少相关的通信成本。我们对该领域的最新提案进行了分类和比较,突出了它们可能的弱点和权衡。然后,我们概述了知识蒸馏在改善联邦学习其他方面的新兴应用。