 RAG
RAG
# RAG(检索增强生成)
LLM的知识仅限于其所训练的数据。 如果你想让LLM了解特定领域的知识或专有数据,可以:
- 使用RAG,我们将在本节中介绍
- 使用你的数据对LLM进行微调
- 结合RAG和微调 (opens new window)
# 什么是RAG?
简单来说,RAG是一种从你的数据中找到并将相关信息注入到提示中的方法,然后再发送给LLM。 通过这种方式,LLM可以获取(希望是)相关的信息,并能够利用这些信息进行回复, 这应该能降低幻觉的概率。
相关的信息可以使用各种 信息检索 (opens new window)方法找到。 最常用的方法包括:
- 全文(关键词)搜索。这种方法使用TF-IDF和BM25等技术, 通过匹配查询中的关键词(例如用户提问内容)与文档数据库中的关键词来搜索文档。 它根据这些关键词在每个文档中的频率和相关性对结果进行排名。
- 向量搜索,也称为“语义搜索”。 文本文档使用嵌入模型转换为数字向量。 然后,根据查询向量与文档向量之间的余弦相似度或其他相似度/距离度量, 找到并排名文档,从而捕捉更深层的语义含义。
- 混合搜索。结合多种搜索方法(例如全文+向量搜索)通常会提高搜索的效果。
目前,本页面主要集中在向量搜索上。 全文和混合搜索目前仅通过Azure AI Search集成支持, 有关更多详细信息,请参见AzureAiSearchContentRetriever。 我们计划在不久的将来扩展RAG工具箱,包含全文和混合搜索。
# RAG阶段
RAG过程分为两个不同的阶段:索引和检索。 LangChain4j提供了这两个阶段的工具。
# 索引
在索引阶段,文档会被预处理,以便在检索阶段能高效地进行搜索。
此过程可能会根据所使用的信息检索方法有所不同。 对于向量搜索,通常涉及清理文档、丰富文档的附加数据和元数据、 将文档拆分为更小的段落(即分块),将这些段落嵌入,最后将它们存储到嵌入存储(即向量数据库)中。
索引阶段通常是离线进行的,这意味着它不需要最终用户等待其完成。 例如,可以通过定时任务在每周末重新索引公司内部文档。 负责索引的代码也可以是一个独立的应用程序,只处理索引任务。
然而,在某些场景下,最终用户可能希望上传自定义文档,使其可以被LLM访问。 在这种情况下,索引应在线进行,并成为主要应用程序的一部分。
下面是索引阶段的简化图示: 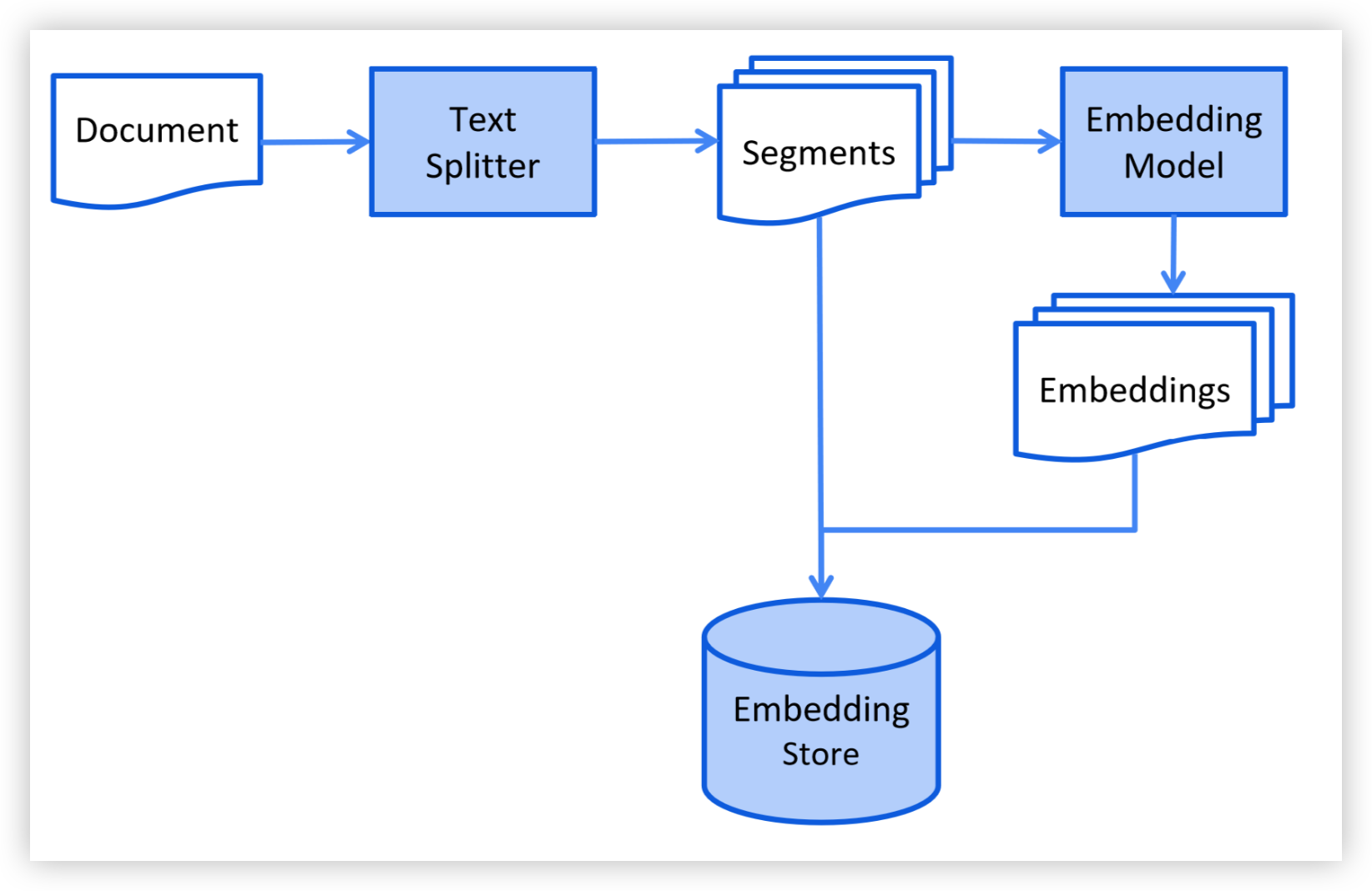
# 检索
检索阶段通常在线进行,当用户提交一个问题时,该问题应通过索引文档来回答。
此过程可能会根据所使用的信息检索方法有所不同。 对于向量搜索,通常涉及将用户的查询(问题)进行嵌入, 并在嵌入存储中进行相似度搜索。 相关的段落(原始文档的片段)将被注入到提示中并发送给LLM。
下面是检索阶段的简化图示: 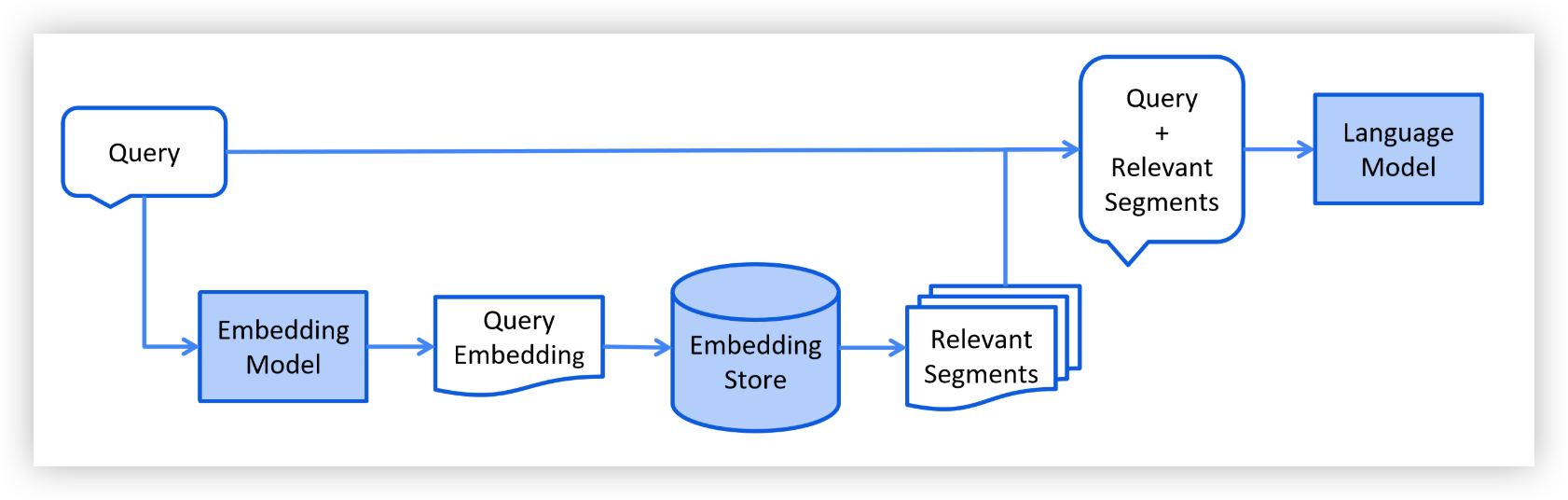
# LangChain4j中的RAG变种
LangChain4j提供了三种RAG变种:
- Easy RAG:最简单的RAG入门方法
- Naive RAG:使用向量搜索的RAG基础实现
- Advanced RAG:一个模块化的RAG框架,允许额外的步骤,例如查询转换、从多个源检索和重新排序
# Easy RAG
LangChain4j有一个“Easy RAG”功能,它使得启动RAG变得尽可能简单。 你不需要了解嵌入、选择向量存储、找到合适的嵌入模型, 也不需要搞清楚如何解析和分割文档等等。 只需指向你的文档,LangChain4j就会为你完成这些。
如果你需要一个可定制的RAG,可以跳到下一节。
如果你使用的是Quarkus,还有一种更简单的方式来做Easy RAG。 请阅读Quarkus文档 (opens new window)。
当然,这种“Easy RAG”的质量会低于量身定制的RAG设置。 然而,这是开始学习RAG和/或制作概念验证的最简单方式。 之后,你可以顺利过渡到更高级的RAG,逐步调整和定制更多的方面。
1. 导入langchain4j-easy-rag依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-alpha1</version>
</dependency>
2
3
4
5
2. 加载你的文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");
这将加载指定目录下的所有文件。
What is happening under the hood?
Apache Tika库支持多种文档类型,用于检测文档类型并进行解析。 由于我们没有明确指定使用哪个DocumentParser, FileSystemDocumentLoader将加载由langchain4j-easy-rag依赖通过SPI提供的ApacheTikaDocumentParser。
How to customize loading documents?
如果你想从所有子目录中加载文档,可以使用loadDocumentsRecursively方法:
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j/documentation");
此外,你还可以通过使用glob或正则表达式来筛选文档:
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation", pathMatcher);
2
当使用loadDocumentsRecursively方法时,你可能需要在glob中使用双星号(而不是单星号): glob:**.pdf。
3. 现在,我们需要预处理并将文档存储在专门的嵌入存储中,也称为向量数据库。 这是为了在用户提问时快速找到相关的信息。 我们可以使用任何15+种支持的嵌入存储, 但为了简化起见,我们将使用内存存储:
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
2
What is happening under the hood?
EmbeddingStoreIngestor通过SPI加载一个DocumentSplitter, 将每个Document拆分成更小的片段(TextSegment), 每个片段最多包含300个标记,并具有30个标记的重叠。EmbeddingStoreIngestor通过SPI加载一个EmbeddingModel, 使用EmbeddingModel将每个TextSegment转换为Embedding。
我们选择了bge-small-en-v1.5 (opens new window)作为Easy RAG的默认嵌入模型。 该模型在MTEB排行榜 (opens new window)上取得了令人印象深刻的成绩, 且其量化版本仅占用24MB的空间。 因此,我们可以轻松地将其加载到内存中,并使用ONNX Runtime (opens new window)在同一进程中运行。
没错,你可以完全离线地将文本转换为嵌入,而无需任何外部服务, 并且可以在同一个JVM进程中运行。 LangChain4j提供了5种流行的嵌入模型 开箱即用 (opens new window)。
- 所有的
TextSegment-Embedding对将存储在EmbeddingStore中。
4.最后一步是创建一个AI服务, 作为我们与LLM的API接口:
interface Assistant {
String chat(String userMessage);
}
ChatLanguageModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在这里,我们将Assistant配置为使用OpenAI LLM来回答用户问题,记住对话中最新的10条消息,并从包含我们文档的EmbeddingStore中检索相关内容。
5. 现在我们准备与它聊天了!
String answer = assistant.chat("如何使用LangChain4j进行Easy RAG?");
# 核心 RAG API
LangChain4j 提供了一套丰富的 API,使您可以轻松构建从简单到复杂的自定义 RAG 管道。在本节中,我们将介绍主要的领域类和 API。
# 文档(Document)
Document 类代表一个完整的文档,例如单个 PDF 文件或网页。目前,Document 只能表示文本信息,但未来的更新将支持图片和表格。
Useful methods:
Document.text()返回Document的文本内容Document.metadata()返回Document的Metadata(请参见下文“Metadata”部分)Document.toTextSegment()将Document转换为TextSegment(请参见下文“TextSegment”部分)Document.from(String, Metadata)从文本和Metadata创建一个DocumentDocument.from(String)从文本创建一个没有Metadata的Document
# 元数据(Metadata)
每个 Document 都包含 Metadata,它存储有关 Document 的元信息,例如其名称、来源、最后更新时间、所有者或其他相关细节。
Metadata 以键值对的形式存储,其中键为 String 类型,值可以是以下类型之一:String、Integer、Long、Float、Double。
Metadata 有多个用途:
- 在将
Document的内容包含在 LLM 的提示中时,可以同时包含元数据条目,为 LLM 提供额外的信息。例如,提供Document的名称和来源可以帮助 LLM 更好地理解内容。 - 在搜索相关内容以包含在提示中时,可以通过
Metadata条目进行过滤。例如,可以将语义搜索限制为仅返回属于特定所有者的Document。 - 当
Document的来源更新时(例如,特定文档的某一页面),可以通过其元数据条目(如“id”、“source”等)轻松找到相应的Document并在EmbeddingStore中更新,以保持同步。
Useful methods:
Metadata.from(Map)从Map创建MetadataMetadata.put(String key, String value)/put(String, int)/ 等,将条目添加到MetadataMetadata.getString(String key)/getInteger(String key)/ 等,返回指定键的Metadata条目的值,并将其转换为所需类型Metadata.containsKey(String key)检查Metadata是否包含指定键的条目Metadata.remove(String key)通过键删除Metadata中的条目Metadata.copy()返回Metadata的副本Metadata.toMap()将Metadata转换为Map
# 文档加载器(Document Loader)
您可以从 String 创建一个 Document,但更简单的方法是使用库中提供的文档加载器之一:
FileSystemDocumentLoader来自langchain4j模块UrlDocumentLoader来自langchain4j模块AmazonS3DocumentLoader来自langchain4j-document-loader-amazon-s3模块AzureBlobStorageDocumentLoader来自langchain4j-document-loader-azure-storage-blob模块GitHubDocumentLoader来自langchain4j-document-loader-github模块GoogleCloudStorageDocumentLoader来自langchain4j-document-loader-google-cloud-storage模块SeleniumDocumentLoader来自langchain4j-document-loader-selenium模块TencentCosDocumentLoader来自langchain4j-document-loader-tencent-cos模块
# 文档解析器(Document Parser)
Document 可以表示多种格式的文件,如 PDF、DOC、TXT 等。为了解析这些格式,库中包含了一个 DocumentParser 接口以及多个实现:
TextDocumentParser来自langchain4j模块,可以解析纯文本格式的文件(如 TXT、HTML、MD 等)ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox模块,可以解析 PDF 文件ApachePoiDocumentParser来自langchain4j-document-parser-apache-poi模块,可以解析 MS Office 文件格式(如 DOC、DOCX、PPT、PPTX、XLS、XLSX 等)ApacheTikaDocumentParser来自langchain4j-document-parser-apache-tika模块,可以自动检测并解析几乎所有现有的文件格式
以下是如何从文件系统加载一个或多个 Document 的示例:
// 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("/home/langchain4j/file.txt", new TextDocumentParser());
// 加载目录中的所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", new TextDocumentParser());
// 加载目录中的所有 *.txt 文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", pathMatcher, new TextDocumentParser());
// 加载目录及其子目录中的所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j", new TextDocumentParser());
2
3
4
5
6
7
8
9
10
11
12
您还可以在不显式指定 DocumentParser 的情况下加载文档。在这种情况下,将使用默认的 DocumentParser。默认解析器是通过 SPI 加载的(例如,从 langchain4j-document-parser-apache-tika 或 langchain4j-easy-rag 加载,如果其中之一被导入)。如果通过 SPI 找不到 DocumentParser,则会回退使用 TextDocumentParser。
# 文档转换器(Document Transformer)
DocumentTransformer 实现可以执行各种文档转换,如:
- 清理:从
Document的文本中删除不必要的噪音,从而节省令牌并减少干扰。 - 过滤:完全排除特定的
Document,以便从搜索中去除。 - 增强:可以为
Document添加附加信息,可能提高搜索结果的质量。 - 摘要:可以对
Document进行摘要,并将其简短的摘要存储在Metadata中,之后可能会包含在每个TextSegment(下文会介绍)中,以提高搜索质量。 - 等等。
在此阶段,还可以添加、修改或删除 Metadata 条目。
目前,提供的唯一开箱即用的实现是 HtmlToTextDocumentTransformer,它来自 langchain4j-document-transformer-jsoup 模块,可以从原始 HTML 中提取所需的文本内容和元数据条目。
由于没有一刀切的解决方案,我们建议实现您自己的 DocumentTransformer,根据您的独特数据进行定制。
# 文本段(Text Segment)
一旦加载了 Document,就可以将它们拆分成更小的片段。LangChain4j 的领域模型包括一个 TextSegment 类,表示 Document 的一个片段。顾名思义,TextSegment 仅能表示文本信息。
To split or not to split?
您可能希望只包含几个相关的片段,而不是整个知识库,以便提供给 LLM。原因有多种:
- LLM 有一个有限的上下文窗口,因此整个知识库可能无法容纳。
- 提供的信息越多,LLM 处理它并响应的时间就越长。
- 提供的信息越多,您需要支付的费用也就越高。
- 提供的信息越多,LLM 可能会因干扰而产生幻觉。
- 提供的信息越多,越难解释 LLM 响应的依据。
为了应对这些问题,可以将知识库拆分成更小、更易处理的片段。片段应该多大呢?这个问题的答案取决于具体情况。
目前有两种广泛使用的方法:
- 每个文档(例如 PDF 文件、网页等)是原子且不可拆分的。在 RAG 管道中检索时,检索 N 个最相关的文档并将其注入到提示中。这种方法适用于需要获取完整文档的情况,例如当某些细节不可或缺时。
- 优点:不会丢失任何上下文。
- 缺点:
- 消耗更多的令牌。
- 有时文档包含多个部分/主题,而其中并非所有内容都与查询相关。
- 向量搜索质量较差,因为不同大小的完整文档被压缩成一个固定长度的向量。
- 将文档拆分成更小的片段,如章节、段落,有时甚至是句子。在 RAG 管道中检索时,检索 N 个最相关的片段并将其注入到提示中。挑战在于确保每个片段提供足够的上下文/信息,以便 LLM 理解。如果上下文丢失,LLM 可能会误解给定的片段。
- 优点:不会丢失上下文,并且每个片段的上下文长度较短,降低了处理成本和干扰。
- 缺点:可能丢失一些上下文,从而影响回答的质量。
Useful methods:
TextSegment.text()返回TextSegment的文本内容。TextSegment.metadata()返回与TextSegment相关的元数据 (Metadata)。TextSegment.from(String, Metadata)从给定的文本和元数据创建一个TextSegment。TextSegment.from(String)从提供的文本创建一个带有空元数据的TextSegment。
# 文档分割器(Document Splitter)
LangChain4j 提供了一个 DocumentSplitter 接口,并附带多个开箱即用的实现:
DocumentByParagraphSplitter(按段落分割)DocumentByLineSplitter(按行分割)DocumentBySentenceSplitter(按句子分割)DocumentByWordSplitter(按单词分割)DocumentByCharacterSplitter(按字符分割)DocumentByRegexSplitter(按正则表达式分割)- 递归分割:
DocumentSplitters.recursive(...)
这些分割器的工作方式如下:
- 实例化一个
DocumentSplitter,指定所需的TextSegment大小,并可选地定义字符或令牌的重叠量。 - 调用
DocumentSplitter的split(Document)或splitAll(List<Document>)方法。 DocumentSplitter将传入的Document拆分成较小的单元,具体拆分方式取决于使用的分割器。例如,DocumentByParagraphSplitter将文档按段落分割(以两个或更多连续换行符定义段落);而DocumentBySentenceSplitter使用 OpenNLP 库的句子检测器将文档分割成句子。DocumentSplitter然后将这些较小的单元(段落、句子、单词等)组合成TextSegment,尽可能在不超过步骤1中设定限制的情况下包含更多单元。如果某些单元仍然太大无法适配TextSegment,将调用一个子分割器。这是另一个可以进一步细化单元的DocumentSplitter。 所有的Metadata条目都会从Document复制到每个TextSegment中。同时,每个文本段都会添加一个唯一的元数据条目index。第一个TextSegment包含index=0,第二个包含index=1,以此类推。
# 文本段转换器(Text Segment Transformer)
TextSegmentTransformer 类似于前面描述的 DocumentTransformer,但它是专门用于转换 TextSegment 的。
与 DocumentTransformer 一样,没有通用的解决方案,因此建议实现一个适合于您特定数据的自定义 TextSegmentTransformer。
一种效果显著的优化检索的技术是,在每个 TextSegment 中包含 Document 的标题或简要摘要。
# 嵌入向量(Embedding)
Embedding 类封装了一个数值向量,表示嵌入内容(通常是文本,例如 TextSegment)的“语义含义”。
更多关于向量嵌入的信息请参考:
- Elastic 的向量嵌入简介 (opens new window)
- Pinecone 的向量嵌入学习资源 (opens new window)
- Google Cloud 的相关博客 (opens new window)
Useful methods
Embedding.dimension()返回嵌入向量的维度(长度)CosineSimilarity.between(Embedding, Embedding)计算两个Embedding之间的余弦相似度Embedding.normalize()对嵌入向量进行归一化(就地操作)
# 嵌入模型(Embedding Model)
EmbeddingModel 接口表示一种特殊类型的模型,可以将文本转换为 Embedding。
目前支持的嵌入模型可以在此处 (opens new window)找到。
Useful methods
EmbeddingModel.embed(String)嵌入给定的文本EmbeddingModel.embed(TextSegment)嵌入给定的TextSegmentEmbeddingModel.embedAll(List<TextSegment>)嵌入给定的多个TextSegmentEmbeddingModel.dimension()返回该模型生成的Embedding的维度
# 嵌入存储(Embedding Store)
EmbeddingStore 接口表示 Embedding 的存储,也称为向量数据库。它支持高效存储和搜索相似(在嵌入空间中接近的)Embedding。
目前支持的嵌入存储可以在此处 (opens new window)找到。
EmbeddingStore 可以单独存储 Embedding,也可以与相应的 TextSegment 一起存储:
- 仅存储
Embedding,通过 ID 标识。原始嵌入数据可存储在其他地方并通过 ID 关联。 - 同时存储
Embedding和嵌入的原始数据(通常是TextSegment)。
Useful methods
EmbeddingStore.add(Embedding)添加一个Embedding到存储中并返回随机生成的 IDEmbeddingStore.add(String id, Embedding)添加一个指定 ID 的EmbeddingEmbeddingStore.add(Embedding, TextSegment)添加一个带关联TextSegment的Embedding,并返回随机 IDEmbeddingStore.addAll(List<Embedding>)添加多个Embedding,返回一组随机 IDEmbeddingStore.addAll(List<Embedding>, List<TextSegment>)添加多个带关联TextSegment的Embedding,返回一组随机 IDEmbeddingStore.search(EmbeddingSearchRequest)搜索最相似的EmbeddingEmbeddingStore.remove(String id)根据 ID 删除一个EmbeddingEmbeddingStore.removeAll()删除所有Embedding
# 嵌入存储器(Embedding Store Ingestor)
EmbeddingStoreIngestor 代表一个数据摄取管道,负责将 Document(文档)摄取到 EmbeddingStore(嵌入存储)中。
在最简单的配置中,EmbeddingStoreIngestor 使用指定的 EmbeddingModel(嵌入模型)将提供的 Document 嵌入,并将它们与相应的 Embedding 存储在指定的 EmbeddingStore 中:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document1);
ingestor.ingest(document2, document3);
IngestionResult ingestionResult = ingestor.ingest(List.of(document4, document5, document6));
2
3
4
5
6
7
8
所有 EmbeddingStoreIngestor 中的 ingest() 方法都会返回一个 IngestionResult(摄取结果)。
IngestionResult 包含有用的信息,包括 TokenUsage(令牌使用情况),显示了为嵌入所使用的令牌数。
可选地,EmbeddingStoreIngestor 可以使用指定的 DocumentTransformer(文档转换器)来转换 Document。
这在你希望在嵌入之前对文档进行清理、增强或格式化时非常有用。
可选地,EmbeddingStoreIngestor 可以使用指定的 DocumentSplitter(文档分割器)将 Document 拆分为 TextSegment(文本段)。
如果 Document 很大,并且你希望将其拆分为较小的 TextSegment 以提高相似性搜索的质量并减少发送到 LLM 的提示的大小和成本,这将非常有用。
可选地,EmbeddingStoreIngestor 可以使用指定的 TextSegmentTransformer(文本段转换器)来转换 TextSegment。
这在你希望在嵌入之前对 TextSegment 进行清理、增强或格式化时非常有用。
示例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
// 为每个文档添加 userId 元数据条目,以便以后能够按它过滤
.documentTransformer(document -> {
document.metadata().put("userId", "12345");
return document;
})
// 将每个文档拆分为每个包含 1000 个令牌的 TextSegment,重叠部分为 200 个令牌
.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenizer()))
// 为每个 TextSegment 添加文档的名称,以提高搜索质量
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 简单的 RAG(Naive RAG)
一旦我们的文档被导入(见前面的章节),我们可以创建一个 EmbeddingStoreContentRetriever 来启用简单的 RAG 功能。
使用 AI Services 时,简单的 RAG 可以按如下方式配置:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5)
.minScore(0.75)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.build();
2
3
4
5
6
7
8
9
10
11
# 高级 RAG
在 LangChain4j 中,可以通过以下核心组件实现高级 RAG:
QueryTransformerQueryRouterContentRetrieverContentAggregatorContentInjector
下图展示了这些组件如何协同工作:
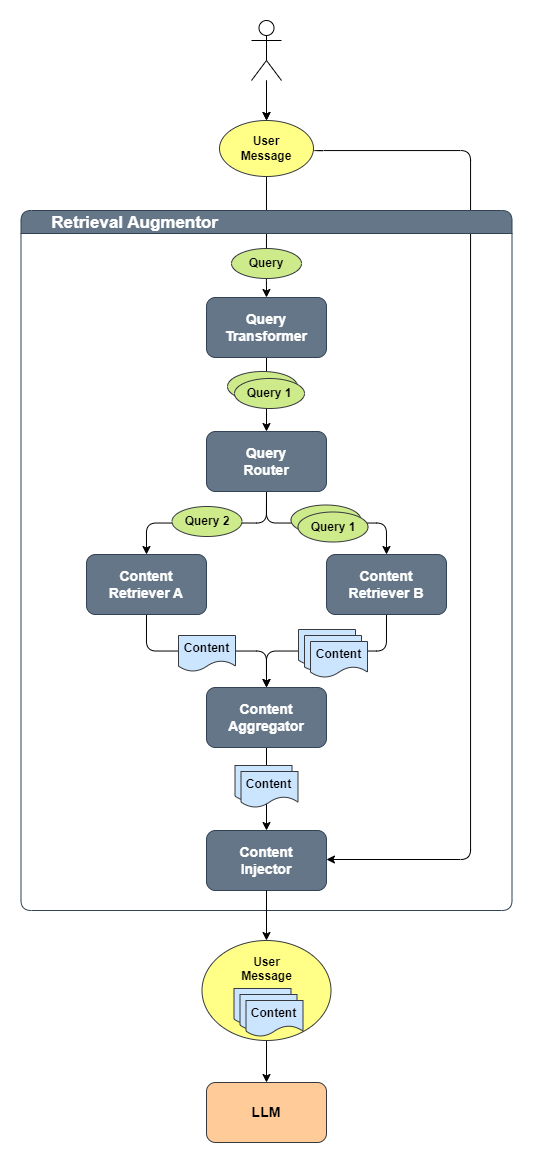
处理流程如下:
- 用户生成一个
UserMessage,该消息被转换为一个Query QueryTransformer将Query转换为一个或多个Query- 每个
Query被QueryRouter路由到一个或多个ContentRetriever - 每个
ContentRetriever为每个Query检索相关的Content ContentAggregator将所有检索到的Content合并为一个最终的排名列表- 这个
Content列表被注入到原始的UserMessage中 - 最后,包含原始查询及注入的相关内容的
UserMessage被发送到 LLM
有关每个组件的详细信息,请参阅 Javadoc。
# 检索增强器(Retrieval Augmentor)
RetrievalAugmentor 是 RAG 流程的入口点。它负责通过从不同来源检索相关的 Content 来增强 ChatMessage。
在创建 AI Service 时,可以指定一个 RetrievalAugmentor 实例:
Assistant assistant = AiServices.builder(Assistant.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();
2
3
4
每次调用 AI 服务时,指定的 RetrievalAugmentor 会被调用来增强当前的 UserMessage。
您可以使用默认实现的 RetrievalAugmentor(如下所述)或实现自定义版本。
# 默认检索增强器(Default Retrieval Augmentor)
LangChain4j 提供了 RetrievalAugmentor 接口的开箱即用实现:DefaultRetrievalAugmentor,它适用于大多数 RAG 用例。该实现灵感来自 这篇文章 (opens new window) 和 这篇论文 (opens new window)。建议阅读这些资源以更好地理解该概念。
# Query
Query 表示 RAG 流程中的用户查询。它包含查询的文本和查询元数据。
# 查询元数据(Query Metadata)
Query 中的 Metadata 包含在 RAG 流程的不同组件中可能有用的信息,例如:
Metadata.userMessage()- 应该增强的原始UserMessageMetadata.chatMemoryId()-@MemoryId注释方法参数的值。更多详情见 这里。这可以用来识别用户并在检索时应用访问限制或过滤器。Metadata.chatMemory()- 所有之前的ChatMessage。这可以帮助了解提问时的上下文。
# Query Transformer
QueryTransformer 将给定的 Query 转换为一个或多个 Query。其目标是通过修改或扩展原始 Query 来提高检索质量。
一些已知的改进检索的方法包括:
- 查询压缩
- 查询扩展
- 查询重写
- 回退提示(Step-back prompting)
- 假设文档嵌入(HyDE)
更多详细信息可以参考 这里 (opens new window)。
# 默认查询转换器(Default Query Transformer)
DefaultQueryTransformer 是 DefaultRetrievalAugmentor 中使用的默认实现。它不会对 Query 进行任何修改,只是直接传递。
# 压缩查询转换器(Compressing Query Transformer)
CompressingQueryTransformer 使用 LLM 将给定的 Query 和之前的对话压缩为一个独立的 Query。这在用户可能会问与之前问题或答案相关的后续问题时非常有用。
例如:
User: Tell me about John Doe
AI: John Doe was a ...
User: Where did he live?
2
3
单独的查询 Where did he live? 无法检索到所需的信息,因为没有明确提到 John Doe,导致无法理解 he 指的是谁。
使用 CompressingQueryTransformer 时,LLM 会读取整个对话,并将 Where did he live? 转换为 Where did John Doe live?。
# 扩展查询转换器(Expanding Query Transformer)
ExpandingQueryTransformer 使用 LLM 将给定的 Query 扩展为多个 Query。这非常有用,因为 LLM 可以以多种方式重新表述和改写查询,从而帮助检索到更多相关内容。
# Content
Content 代表与用户查询相关的内容。目前,它仅限于文本内容(即 TextSegment),但未来可能支持其他模态(例如图像、音频、视频等)。
# Content Retriever
ContentRetriever 使用给定的 Query 从底层数据源中检索 Content。底层数据源可以是几乎任何东西:
- 嵌入存储
- 全文搜索引擎
- 向量和全文搜索的混合
- 网络搜索引擎
- 知识图谱
- SQL 数据库
- 等等
ContentRetriever 返回的 Content 列表按相关性排序,从最高到最低。
# 嵌入存储内容检索器(Embedding Store Content Retriever)
EmbeddingStoreContentRetriever 使用 EmbeddingModel 将 Query 嵌入,进而从 EmbeddingStore 中检索相关的 Content。
例如:
EmbeddingStore embeddingStore = ...
EmbeddingModel embeddingModel = ...
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
// maxResults 也可以根据查询动态指定
.dynamicMaxResults(query -> 3)
.minScore(0.75)
// minScore 也可以根据查询动态指定
.dynamicMinScore(query -> 0.75)
.filter(metadataKey("userId").isEqualTo("12345"))
// filter 也可以根据查询动态指定
.dynamicFilter(query -> {
String userId = getUserId(query.metadata().chatMemoryId());
return metadataKey("userId").isEqualTo(userId);
})
.build();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Web 搜索内容检索器(Web Search Content Retriever)
WebSearchContentRetriever 使用 WebSearchEngine 从网络中检索相关的 Content。
所有支持的 WebSearchEngine 集成可以在 这里 (opens new window) 查找。
例如:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();
2
3
4
5
6
7
8
9
完整示例可以参考 这里 (opens new window)。
# SQL 数据库内容检索器(SQL Database Content Retriever)
SqlDatabaseContentRetriever 是 ContentRetriever 的一个实验性实现,位于 langchain4j-experimental-sql 模块中。
它使用 DataSource 和 LLM 来生成和执行 SQL 查询,以应对给定的自然语言查询。
有关更多信息,请参阅 SqlDatabaseContentRetriever 的 javadoc。
# Azure AI 搜索内容检索器
AzureAiSearchContentRetriever 是与 Azure AI Search (opens new window) 的集成。
它支持全文、本地化和混合搜索,并提供重新排序功能。
它可以在 langchain4j-azure-ai-search 模块中找到。
更多信息请参阅 AzureAiSearchContentRetriever 的 Javadoc。
# Neo4j 内容检索器
Neo4jContentRetriever 是与 Neo4j (opens new window) 图形数据库的集成。
它将自然语言查询转换为 Neo4j Cypher 查询,并通过在 Neo4j 中运行这些查询来检索相关信息。
它可以在 langchain4j-neo4j 模块中找到。
# 查询路由器
QueryRouter 负责将 Query 路由到适当的 ContentRetriever(内容检索器)。
# 默认查询路由器
DefaultQueryRouter 是 DefaultRetrievalAugmentor 中使用的默认实现。
它将每个 Query 路由到所有配置的 ContentRetriever。
# 语言模型查询路由器
LanguageModelQueryRouter 使用 LLM 来决定将给定的 Query 路由到哪里。
# 内容聚合器
ContentAggregator 负责聚合来自以下来源的多个排名列表的 Content(内容):
- 多个
Query - 多个
ContentRetriever - 两者结合
# 默认内容聚合器
DefaultContentAggregator 是 ContentAggregator 的默认实现,
执行两阶段的倒排排名融合(Reciprocal Rank Fusion,RRF)。
更多详情请参阅 DefaultContentAggregator 的 Javadoc。
# 重新排序内容聚合器
ReRankingContentAggregator 使用 ScoringModel(如 Cohere)进行重新排序。
支持的评分(重新排序)模型的完整列表可以在 此处 (opens new window) 查找。
更多详情请参阅 ReRankingContentAggregator 的 Javadoc。
# 内容注入器
ContentInjector 负责将由 ContentAggregator 返回的 Content(内容)注入到 UserMessage 中。
# 默认内容注入器
DefaultContentInjector 是 ContentInjector 的默认实现,它会简单地将 Content 添加到 UserMessage 的末尾,并以 Answer using the following information: 为前缀。
你可以通过以下三种方式自定义如何将 Content 注入到 UserMessage 中:
- 覆盖默认的
PromptTemplate:
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("{{userMessage}}\n{{contents}}"))
.build())
.build();
2
3
4
5
请注意,PromptTemplate 必须包含 和 变量。
- 扩展
DefaultContentInjector并覆盖其中一个format方法 - 实现自定义的
ContentInjector
DefaultContentInjector 还支持将从检索到的 Content.textSegment() 中注入 Metadata 条目:
DefaultContentInjector.builder()
.metadataKeysToInclude(List.of("source"))
.build()
2
3
在这种情况下,TextSegment.text() 将以 "content: " 前缀开始,
每个来自 Metadata 的值将以键为前缀。
最终的 UserMessage 将如下所示:
How can I cancel my reservation?
Answer using the following information:
content: To cancel a reservation, go to ...
source: ./cancellation_procedure.html
content: Cancellation is allowed for ...
source: ./cancellation_policy.html
2
3
4
5
6
7
8
# 并行化
当只有一个 Query 和一个 ContentRetriever 时,DefaultRetrievalAugmentor 在同一个线程中执行查询路由和内容检索。
否则,会使用 Executor 来并行化处理。
默认情况下,使用修改过的(keepAliveTime 为 1 秒,而不是 60 秒)Executors.newCachedThreadPool(),
但你可以在创建 DefaultRetrievalAugmentor 时提供自定义的 Executor 实例:
DefaultRetrievalAugmentor.builder()
...
.executor(executor)
.build;
2
3
4
# 访问来源
如果你希望访问在使用 AI 服务 时用于增强消息的来源(检索到的 Content),
你可以通过将返回类型包装在 Result 类中轻松访问:
interface Assistant {
Result<String> chat(String userMessage);
}
Result<String> result = assistant.chat("How to do Easy RAG with LangChain4j?");
String answer = result.content();
List<Content> sources = result.sources();
2
3
4
5
6
7
8
9
当进行流式处理时,可以使用 onRetrieved() 方法指定一个 Consumer<List<Content>>:
interface Assistant {
TokenStream chat(String userMessage);
}
assistant.chat("How to do Easy RAG with LangChain4j?")
.onRetrieved(sources -> ...)
.onNext(token -> ...)
.onError(error -> ...)
.start();
2
3
4
5
6
7
8
9
10
# 示例
- 简单 RAG (opens new window)
- 朴素 RAG (opens new window)
- 带查询压缩的高级 RAG (opens new window)
- 带查询路由的高级 RAG (opens new window)
- 带重新排序的高级 RAG (opens new window)
- 包含元数据的高级 RAG (opens new window)
- 带元数据过滤的高级 RAG (opens new window)
- 多个检索器的高级 RAG (opens new window)
- 带网页搜索的高级 RAG (opens new window)
- 带 SQL 数据库的高级 RAG (opens new window)
- 跳过检索 (opens new window)
- RAG + 工具 (opens new window)
- 加载文档 (opens new window)