 FedFD&FAug:Communication-Efficient On-Device Machine Learning:Federated Distillation and Augmentation under Non-IID Private Data
FedFD&FAug:Communication-Efficient On-Device Machine Learning:Federated Distillation and Augmentation under Non-IID Private Data
# FedFD&Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
# 摘要
设备端机器学习(On-device ML)使训练过程能够利用大量用户生成的私有数据样本。为了充分利用这一优势,需要尽量减少设备间的通信开销。为此,我们提出了联邦蒸馏(Federated Distillation, FD),这是一种分布式模型训练算法,其通信负载大小远小于基准方案——联邦学习(Federated Learning, FL),特别是在模型规模较大时。此外,用户生成的数据样本在设备间往往呈现非独立同分布(non-IID),与独立同分布(IID)数据集相比,这种情况通常会导致性能下降。为了解决这一问题,我们提出了联邦增强(Federated Augmentation, FAug),该方法通过各设备协同训练一个生成模型,从而扩充本地数据以生成接近IID的数据集。实验研究表明,结合FAug的FD相比FL通信开销减少约26倍,同时在测试准确率上可达到95%-98%。
# 1 引言
大规模训练数据集推动了现代机器学习(ML)的革命性发展。设备端机器学习(On-device ML)可以通过利用由移动设备生成并持有的大量私有数据样本,推动下一阶段的演进 [1, 2]。通过保护数据隐私,可以实现对这些数据的访问,即通过交换设备的本地模型参数,而非直接共享私有数据,来协作训练全局模型,联邦学习(Federated Learning, FL)正是这种方法的典型代表 [3-9]。
然而,在FL中,每个设备侧执行训练过程会产生与模型大小成正比的通信开销,这使得使用大规模模型变得不可行。此外,用户生成的训练数据集在设备间往往是非独立同分布(non-IID)的。与独立同分布(IID)数据集相比,在FL框架下,这种非IID性会导致预测准确率下降,例如在MNIST数据集上下降高达11%,在CIFAR-10数据集上下降高达51% [9]。虽然通过交换数据样本可以部分恢复精度,但这可能会引发过量的通信开销和隐私泄露。
基于此,我们寻求一种在非IID私有数据环境下通信高效的设备端机器学习方法。为了提高通信效率,我们提出了联邦蒸馏(Federated Distillation, FD),这是一种分布式在线知识蒸馏方法,其通信负载大小取决于模型输出维度而非模型大小。在运行FD之前,我们通过联邦增强(Federated Augmentation, FAug)校正非IID的训练数据集。这是一种基于生成对抗网络(GAN)的数据增强方案,在隐私泄露和通信开销之间权衡下协同训练。经过训练的GAN使得每个设备能够在本地再现所有设备的数据样本,从而使训练数据集接近IID分布。
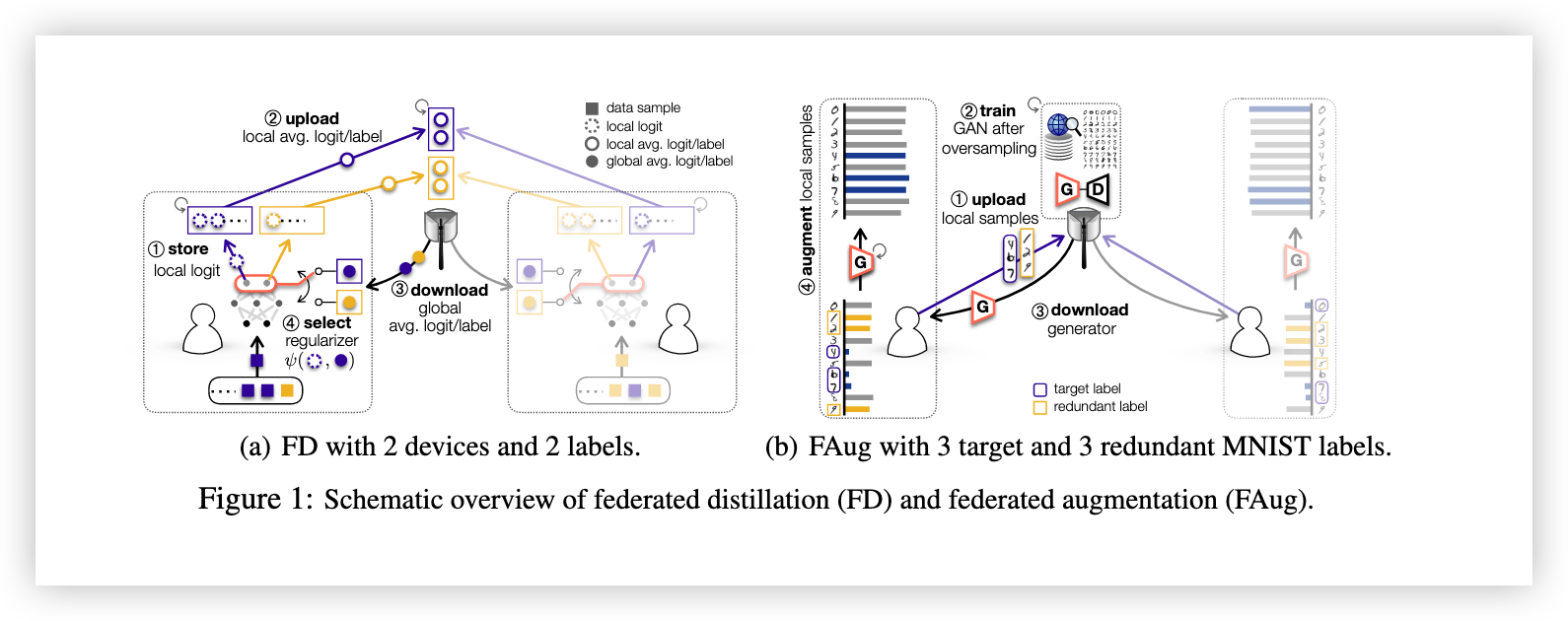
# 2 Federated Distillation
传统的分布式训练算法在每个迭代周期交换本地模型参数。在无线互联的设备端机器学习(On-device ML)中,这会导致显著的通信开销。联邦学习(Federated Learning, FL)通过间隔交换模型参数来降低通信成本 [3–9]。在这种周期性通信的基础上,提出的联邦蒸馏(Federated Distillation, FD)不交换模型参数,而是交换模型输出,从而使设备端ML可以采用大规模的本地模型。
FD 的基本操作流程遵循在线版本的知识蒸馏(Knowledge Distillation, KD)[10],也称为协同蒸馏(Co-Distillation, CD)[11]。在 CD 中,每个设备将自身视为学生,并将所有其他设备的平均模型输出视为教师的输出。每个模型输出是一组通过 softmax 函数归一化的 logit 值,以下称为 logit 向量,其大小由标签数量决定。教师与学生输出的差异通过交叉熵计算,作为学生的损失正则项,称为蒸馏正则项,从而在分布式训练过程中获取其他设备的知识。
然而,CD 的通信效率较低,其原因在于每个 logit 向量与输入训练数据样本相关联。为了进行知识蒸馏,教师和学生的输出必须使用相同的训练数据样本进行评估。这种要求不允许周期性交换模型输出,而是需要交换与训练数据集大小等量的模型输出,或者交换模型参数以便在本地重建教师模型,从而与学生模型同步生成输出 [11]。
为了解决这一问题,FD 中的每个设备存储按标签平均的 logit 向量,并周期性地将这些本地平均 logit 向量上传到服务器。对于每个标签,从所有设备上传的本地平均 logit 向量取平均值,生成每个标签的全局平均 logit 向量。所有标签的全局平均 logit 向量下载到各设备。当每个设备计算蒸馏正则项时,教师的输出被选为与当前训练样本标签相同的全局平均 logit 向量。
FD 的上述操作在图1(a)中可视化,并由算法1详细说明。以下是符号定义:
- 集合
表示所有设备的完整训练数据集, 表示每个设备的批数据。 - 函数
是通过 softmax 函数归一化的 logit 向量,其中 和 分别是模型的权重和输入。 - 函数
是交叉熵,用于损失函数和蒸馏正则项。 - 常数
是学习率, 是蒸馏正则项的权重参数。 - 在第
个设备上, 是当训练样本属于第 个真实标签时,第 次迭代的本地平均 logit 向量。 是全局平均 logit 向量,计算公式如下:
其中
# 算法1 联邦蒸馏(FD)

# 3 Federated Augmentation (FAug)
在设备端机器学习(On-device ML)中,非独立同分布(Non-IID)的训练数据集可以通过从其他设备获取缺失的本地数据样本来纠正 [9]。然而,这种方法可能会带来显著的通信开销,特别是在设备数量庞大的情况下。为了克服这一问题,我们提出了联邦增强(Federated Augmentation, FAug),每个设备可以通过生成模型在本地生成缺失的数据样本。
生成模型在计算能力强且连接互联网速度快的服务器上进行训练。在 FAug 中,每个设备识别缺乏数据样本的标签(称为目标标签),并通过无线连接将少量目标标签的数据样本上传到服务器。服务器通过过采样(例如,使用 Google 的图像搜索工具处理视觉数据)扩展上传的种子数据样本,以训练一个条件生成对抗网络(Conditional GAN, cGAN)[12]。最后,将训练好的 GAN 的生成器下载到每个设备,允许设备补充目标标签的数据,直到达到独立同分布(IID)的训练数据集。这种方法显著减少了与直接交换数据样本相比的通信开销。如图1(b)所示,该过程的操作方式如下:
# 隐私保护机制
FAug 的操作需要保证用户生成数据的隐私。事实上,每个设备的数据生成偏差(即目标标签)可能泄露其隐私敏感信息,例如患者的医疗检查项目可能暴露诊断结果。为保护目标标签不被服务器知晓,设备还需上传目标标签以外的冗余标签数据样本。由此产生的设备到服务器的隐私泄露(Device-Server Privacy Leakage, PL)以额外的上行通信开销为代价得以减少。在第
其中,
此外,设备的目标标签信息可能通过共享的生成器泄露给其他设备。实际上,一个设备可以通过识别其下载生成器能够生成的标签,推测其他设备的目标标签。这种隐私泄露被定义为设备间隐私泄露(Inter-Device PL)。假设 GAN 对所有目标标签和冗余标签始终完美训练,第
需要注意的是,当分母等于最大值(即标签的总数)时,设备间隐私泄露达到最小值。这种最小泄露可以通过增加设备数量实现,而与目标标签和冗余标签的大小无关。
# 4 Evaluation
在本节中,我们在非IID的MNIST训练数据集下评估了提出的FD和FAug方法,数据集的构造过程如下:在包含55,000个样本的MNIST训练数据集中,均匀随机选择2,000个样本,并将其分配到每个设备。每组2,000个样本根据真实标签被划分为10个子集。在每个设备上,均匀随机选择具有预定义数量的目标标签,并删除目标标签中约97.5%的样本,使每个目标标签包含5个样本。
# 实验设置
在上述非IID的MNIST训练数据集上,每个设备拥有一个5层的卷积神经网络(CNN),包括2个卷积层、1个最大池化层以及2个全连接层。设备以批量大小为64进行本地训练。作为FD的对比基准,我们考虑了带或不带FAug的联邦学习(FL) [4]。在FD和FL中,每个设备在与其他设备交换信息之前执行250次本地模型更新(即 n=250n = 250),构成一次全局迭代。此过程最多重复16次全局迭代。
对于每次全局迭代,FD在上行和下行方向分别交换100个logits,每个logit由10个包含10个元素的logit向量组成。相比之下,FL每次全局迭代在上下行方向均需交换CNN的1,199,648个模型参数。
在FAug中,服务器拥有一个条件生成对抗网络(GAN),包括一个4层生成器神经网络和一个4层判别器神经网络。下载训练好的生成器时,通信开销与生成器模型的大小成正比,其参数总数为1,493,520。
# 实验结果
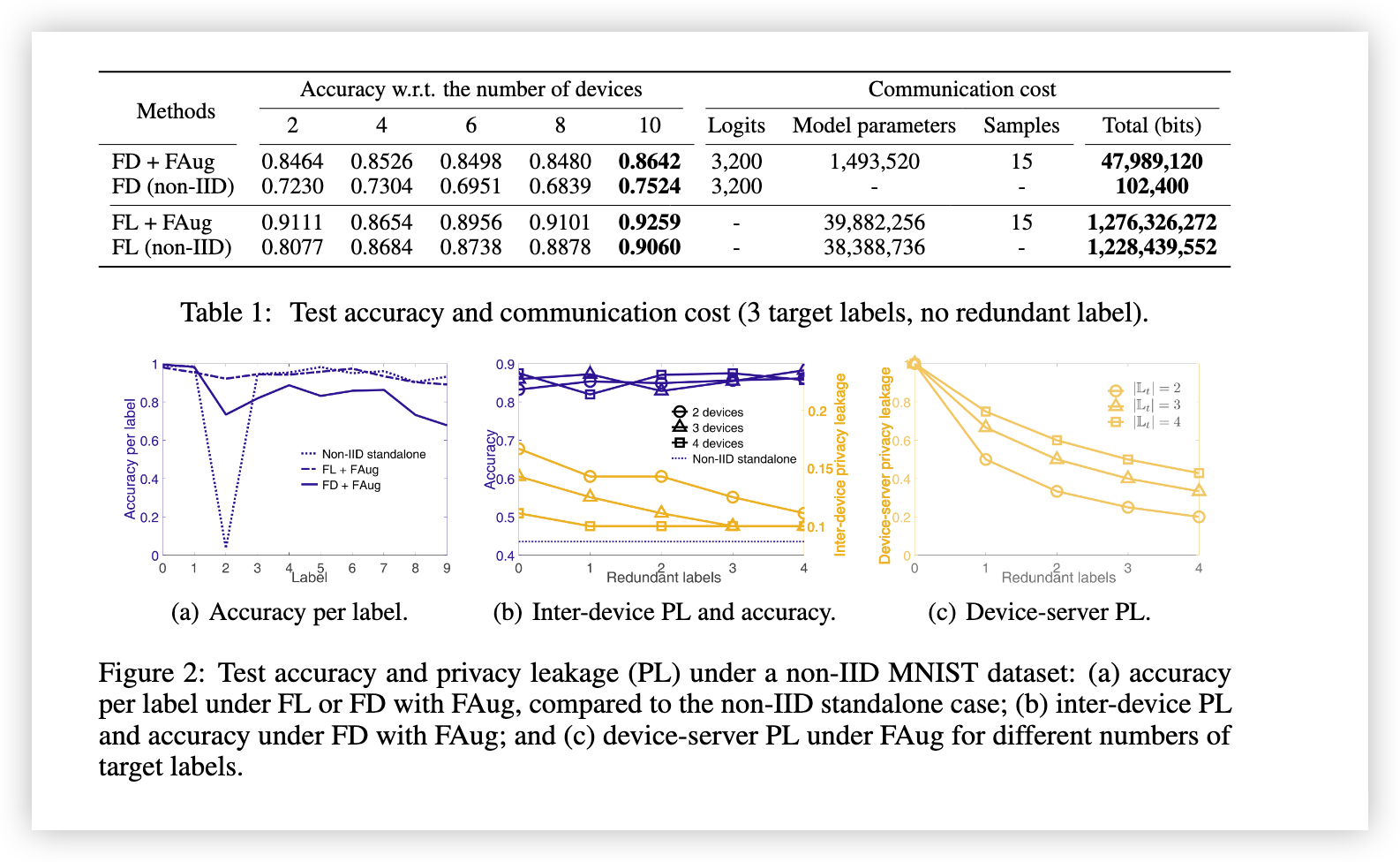
在均匀随机选择的参考设备上,表1展示了FD和FL(带或不带FAug)的测试准确率和通信成本。
- 通信成本定义:
- 对于FD,通信成本为交换的logits数量。
- 对于FL,通信成本为交换的模型参数数量。
- 对于FAug,通信成本包括上传的数据样本数量和下载的训练生成器的模型参数数量。
每种方法的总通信成本基于以下假设进行评估:MNIST样本的每个像素(28x28像素)占用8位,而每个logit和每个模型参数均消耗32位。
# 结果分析
- 通信效率与准确率:
- 表1显示,与FL相比,FD显著降低了通信成本,同时测试准确率略有下降。
- FAug能够补偿FD的精度损失,而不会产生显著的通信开销。
- 在不同设备数量下,与FL相比,FD的测试准确率为77%-90%,通过FAug可提高到95%-98%。FD和FAug的总通信成本仍然约为FL的1/26。
- 非IID数据的影响:
- FL对非IID数据集更具鲁棒性。
- FAug使FD的测试准确率提升了7%-22%,使FL的测试准确率提升了0.8%-2.7%。
- 测试准确率与隐私泄漏:
- 图2(a)展示了当“2”为目标标签时的每标签测试准确率。对于目标标签,参考设备在原始非IID数据集下的单独训练测试准确率为3.585%,通过FAug与FD或FL结合,可分别提升至73.44%和92.19%。
- 图2(b)显示,对于所有标签,FAug结合FD相比于单独训练的测试准确率提高了约2倍,且与设备数量及冗余标签数量无关。
- 图2(c)说明,设备与服务器之间的隐私泄漏(PL)随着冗余标签数量增加而减少,随着目标标签数量增加而增加。
# 5 Concluding Remarks
为了实现设备端机器学习(On-device ML),我们提出了通信高效的训练算法 FD 和数据增强算法 FAug。实证研究表明,与联邦学习(FL)相比,这些方法在通信开销显著减少的同时实现了相当高的准确率。
# Future Work
在未来的研究中,FD 的性能可以通过一些小的修改进一步提升。实际上,随着训练的进行,模型输出的准确性会逐渐提高。因此,在本地对 Logit 进行平均时,采用与本地计算时间成正比的加权平均可能会更优。此外,为了在通信效率和准确性之间取得平衡,可以结合使用 FD 和 FL。例如,考虑到下行无线通信链路通常比上行更快 [13],可以在上行使用 FD,而在下行使用 FL。
最后,利用差分隐私框架 [8],通过在上传的种子数据样本中插入适当数量的噪声,可以改善 FAug 的隐私保护能力。这也是未来研究中一个有趣的方向。
# Acknowledgement
本研究部分得到了以下项目的支持:
- 国防采办项目管理局资助的生物仿生机器人研究中心 (UD160027ID);
- 芬兰科学院项目 CARMA 和 6Genesis Flagship (grant no. 318927);
- INFOTECH 项目 NOOR;
- Kvantum Institute 战略项目 SAFARI;
- 韩国国家研究基金会 (NRF) 的基础科学研究计划,由科学与信息通信技术部资助 (NRF-2017R1A2A2A05069810)。