 审查代码请求
审查代码请求
# 第四部分:代码请求审核

到目前为止,我们已经了解了 Rachel 如何通过 PySyft 提交研究项目,现在该项目正等待 Owen(数据所有者)审核。
# 你将学到什么?
完成第四部分后,您将学会:
- 如何访问收到的项目请求;
- 如何审核用户代码;
- 如何批准代码请求。
# 4.1 审核收到的请求

第一步是登录 Datasite。这次,我们将使用 Owen 的数据所有者身份登录。
import syft as sy
data_site = sy.orchestra.launch(name="cancer-research-centre")
client = data_site.login(email="owen@cancer-research.science", password="cancer_research_syft_admin")
2
3
4
5
随后,可以通过客户端访问现有的项目:
client.projects
如预期,Datasite 中目前包含 Rachel 提交的 "Breast Cancer ML Project" 请求。通过查看描述,Owen 可以大致了解即将收到的代码请求的意图。
接下来,我们可以访问具体的请求以进一步检查。通过索引访问现有请求:
request = client.requests[0]
request
2
从请求对象开始,我们可以立即获得与其关联的代码引用。这些代码对应于数据科学家提交并附加到原始项目的代码。
在测试代码执行之前,数据所有者可以先审查代码,确认项目描述中设定的预期是否得到满足:
request.code
[!WARNING]
隐私与安全代码审查
在批准之前,代码审查必须通过安全和隐私评估。为确保隐私受到保护,数据所有者必须检查代码是否遵守其数据发布规则。为确保安全,应注意防范恶意代码请求。以下是一些可能有用的安全代码审查资源:
# 4.2 执行代码
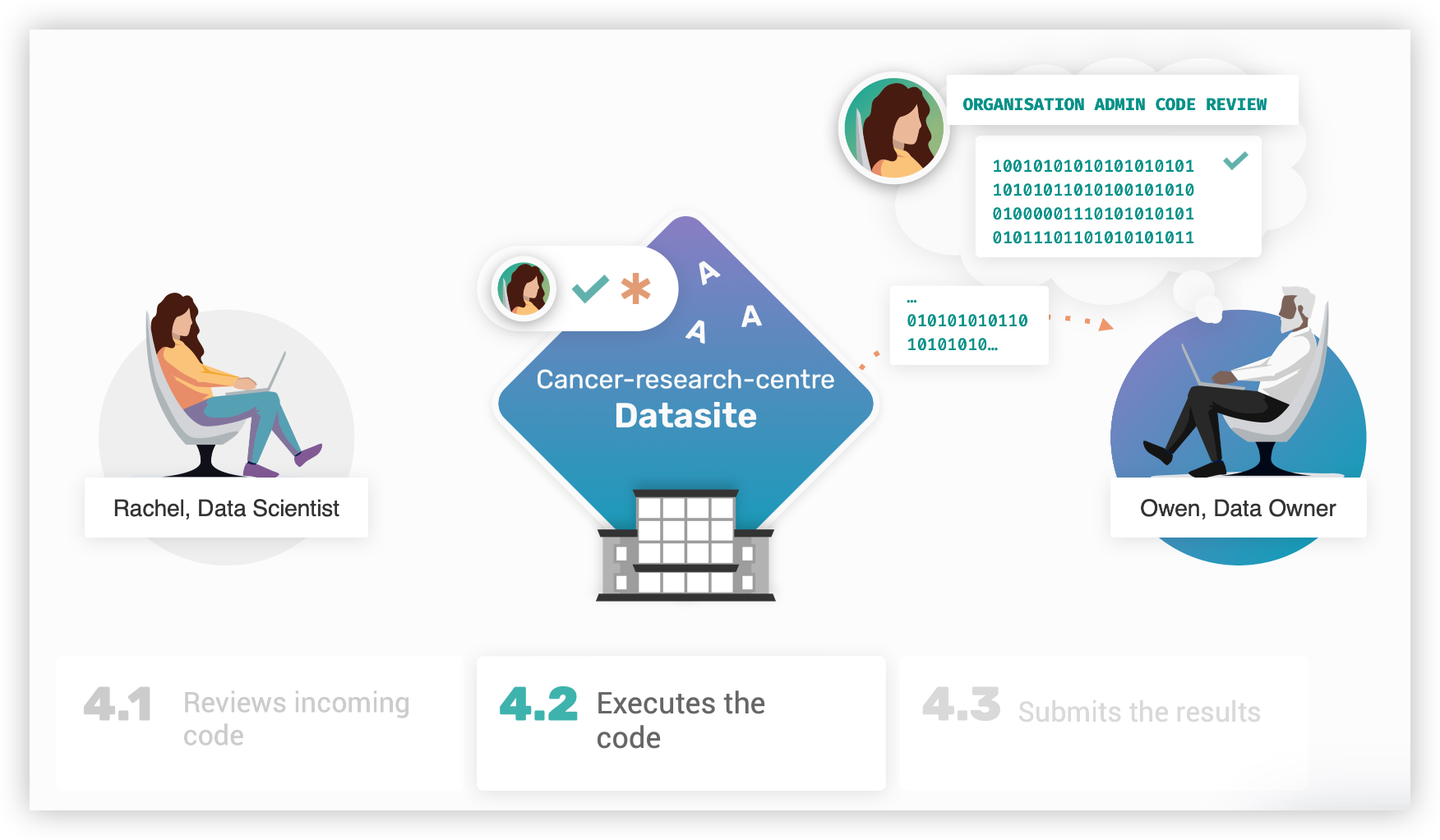
在审查代码后,Owen 的下一步是分别在模拟数据和真实数据上执行代码,这些数据存储在提交代码中指定的资产中。审查 Rachel 的代码后,我们可以看到该函数需要 "Breast Cancer Biomarker" 数据集中的特征和标签资产。
首先,获取指定的 Syft 函数引用:
syft_function = request.code
然后,获取所需的资产:
bc_dataset = client.datasets["Breast Cancer Biomarker"]
features, labels = bc_dataset.assets
2
此时,数据所有者可以首先在 features.mock 和 labels.mock 上运行 syft_function,随后在 features.data 和 labels.data 上重复相同的操作:
result_mock_data = syft_function.run(features_data=features.mock, labels=labels.mock)
result_mock_data
2
[!NOTE]
模拟数据上的执行
模拟数据的结果与第三部分中 Rachel 代码获得的结果完全一致。这是因为 Rachel 的代码正确地使用了随机种子,从而保证了结果的可复现性。
确认代码在模拟数据上运行正确后,我们可以在真实数据上测试代码,并收集 Rachel 所需的结果:
result_real_data = syft_function.run(features_data=features.data, labels=labels.data)
result_real_data
2
# 4.3 批准请求

现在,Owen 已经审查、检查并测试了 Rachel 的函数在选定资产上的运行,同时收集了真实非公开数据上的结果,他可以继续批准代码请求:
request.approve()
我们可以通过查看当前可用请求的状态来验证请求是否已获批准:
client.requests
如预期,Rachel 的请求状态现在已变为 Approved。
# 恭喜完成第四部分 🎉
祝贺您完成教程的第四部分!👏
在本部分中,我们探索了请求审核和批准的完整工作流程。特别是,在收到 Rachel 的新请求后,Owen 可以阅读她研究的目的,审查提交的代码,并检查所有预期和数据访问标准是否满足。最后,在模拟数据和真实数据上执行代码后,请求被批准。
# 展望第五部分
在最后一部分中,我们将看到 Rachel 如何在请求获得批准后,检索她所期望的结果。