 面试场景题
面试场景题
# 1.开发中慢SQL怎么优化
慢 SQL 通常指执行时间过长(如超过 1 秒)的 SQL 语句,优化需从定位 → 分析 → 优化 → 监控 分析。
我认为,一个 SQL 执行的很慢,我们要分两种情况讨论:
1. 大多数情况下很正常,偶尔很慢,则有如下原因:
(1) 数据库在 刷新脏页 ,例如 redo log 写满了需要同步到磁盘。
(2) 执行的时候, 遇到锁 ,如表锁、行锁。
(3) sql写的烂 了
2.这条 SQL 语句一直执行的很慢,则有如下原因:
(1) 没有用上索引或则索引失效:例如该字段没有索引;或则由于对字段进行运算、函数操作导致无法用索引。
(2) 有索引可能会走全表扫描
# 1.1 开启慢查询日志
慢查询日志(Slow Query Log)用于记录执行时间超过指定阈值的 SQL,是定位慢 SQL 的第一步。
# 临时开启(实时生效)
SET GLOBAL slow_query_log = ON; -- 开启慢查询日志
SET GLOBAL long_query_time = 1; -- 超过 1 秒记录
SET GLOBAL log_queries_not_using_indexes = ON; -- 未使用索引的 SQL 也记录
2
3
注:
long_query_time的单位是秒,可设置成小数,如0.5。
查看开启状态:
SHOW VARIABLES LIKE '%slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';
2
查看慢查询日志文件路径:
SHOW VARIABLES LIKE 'slow_query_log_file';
# 永久开启(修改 my.cnf/my.ini)
在 MySQL 配置文件 [mysqld] 下加入:
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
log_queries_not_using_indexes = 1
2
3
4
5
修改后重启 MySQL:
systemctl restart mysqld
# 1.2 检查并优化索引
缺失索引:通过EXPLAIN分析执行计划,若type为ALL(全表扫描),需为WHERE、JOIN、ORDER BY字段添加索引。
无效索引:删除重复索引(如同一字段多次建索引)、冗余索引(如联合索引中前缀字段已单独建索引)。
使用额外空间存储:Using filesort = 需要一个额外的排序阶段(通常因为排序不能直接用索引);Using temporary = 需要内部临时表用于去重/分组/合并/物化(不总是跟排序有关,但经常与 filesort 一起出现)。
索引失效场景:
- 避免使用
SELECT *(可能导致覆盖索引失效)。 - 警惕函数 / 表达式操作索引字段(如
WHERE SUBSTR(name,1,3)='abc')。 - 避免
!=、NOT IN、IS NOT NULL(可能导致索引失效,视数据库版本而定)。
# 1.3优化 SQL 语句结构
- 拆分大 SQL:将复杂
JOIN拆分为多个单表查询(尤其多表联查超过 3 张时),减少锁竞争。 - 避免子查询:子查询可能导致临时表创建,改用
JOIN优化(如SELECT * FROM t1 WHERE id IN (SELECT id FROM t2)改为JOIN)。 - 限制返回行数:使用
LIMIT分页,避免一次性返回大量数据。
# 1.4 数据库配置与架构优化
- 调整参数:增大
innodb_buffer_pool_size(MySQL)、shared_buffers(PostgreSQL),减少磁盘 IO。 - 分库分表:当单表数据量超过 1000 万行时,采用水平分表(按时间、用户 ID)或垂直分表(拆分大字段至单独表)。
- 读写分离:通过主从复制,将读请求分流到从库,减轻主库压力。
# 1.5 总结
“慢 SQL 我一般分四步处理:首先开启慢查询日志定位问题 SQL,然后用 EXPLAIN 查看执行计划,重点看是否出现全表扫描、Using filesort 或 Using temporary。第二步是优化索引,包括为 WHERE、JOIN、ORDER BY 字段补索引,避免函数操作、隐式转换、前模糊匹配导致的索引失效,并尽量使用覆盖索引。第三步是改写 SQL 结构,遇到复杂多表 JOIN 会做拆分,子查询改成 JOIN,大分页用延迟关联。最后是数据库层面调优:提升 buffer_pool 缓冲命中率,必要时做读写分离或分库分表。通过这套流程基本都能把慢 SQL 优化到毫秒级。”
# 2. JVM 内存 OOM 排查思路
# 2.1 虚拟机栈 OOM 的排查与处理
常见报错信息
java.lang.StackOverflowError:方法调用栈过深导致栈空间不足。java.lang.OutOfMemoryError: unable to create new native thread:线程数量过多,耗尽了可用栈内存。
触发原因
- 递归过深
- 递归无终止条件或调用层次过多,单线程栈帧无限增加。
- 线程过多
- 无限制地创建新线程(如线程池未做上限控制),每个线程都会分配独立的栈内存,导致整体超出系统限制。
排查与解决方案
- 递归过深
- 查看错误堆栈(
Stack Trace),定位递归调用方法。 - 检查递归终止条件是否正确。
- 调整栈内存大小:通过
-Xss参数(如-Xss256k)修改单线程栈大小。 - 代码优化:递归改循环,减少调用深度。
- 查看错误堆栈(
- 线程过多
- 使用
jstack <PID>检查线程数量;若线程数过高(如上万),需确认是否存在无限制创建线程的问题。 - 优化线程池配置:合理设置
corePoolSize、maximumPoolSize,避免无限制扩张。 - 复用线程:使用线程池代替频繁创建新线程。
- 使用
# 2.2 堆内存 OOM 的排查与处理
触发原因
- 对象过多,超过堆空间上限,内存溢出
- 程序中创建了大量对象,且存活时间较长,GC 无法及时回收。
- 常见场景:大集合(
List/Map)无限增长、读取大文件数据全部加载进内存等。
- 内存泄漏(Memory Leak)
- 无用对象仍然被引用,GC 无法释放内存。
- 常见场景:静态集合缓存未清理、未关闭的连接对象(JDBC、IO、Socket)、监听器未移除等。
排查与解决方案
- 确认是否为内存不足
- 调整堆内存大小:通过
-Xmx和-Xms参数增加堆空间(如-Xms512m -Xmx2g)。 - 检查是否有必要在 JVM 层面扩大堆,或通过代码优化减少对象占用。
- 调整堆内存大小:通过
- 定位内存泄漏
- 使用内存分析工具:
jmap -dump:format=b,file=heap.hprof <PID>导出堆快照。- 使用工具(如 Eclipse MAT、VisualVM、JProfiler、YourKit)分析对象引用关系,定位泄漏点。
- 常见优化措施:
- 清理无用的缓存数据,避免静态集合无限增长。
- 使用弱引用(
WeakReference/SoftReference)存储缓存对象。 - 确保关闭资源(数据库连接、文件流、网络连接等)。
- 移除不再使用的监听器或回调。
- 使用内存分析工具:
# 3. CPU 飙升如何排查
在 Java 应用运行过程中,若某一线程进入死循环、频繁 GC 或大量上下文切换,可能导致 CPU 使用率飙升,影响系统整体性能。
# 3.1 常见表现
top/htop查看进程 CPU 使用率持续高企(单核常见为 100%)。- 系统负载过高(
load average远超 CPU 核数)。 - 应用响应缓慢,甚至无响应。
# 3.2 常见原因
- 代码层面
- 死循环 / 无限递归(如
while(true)无 sleep)。 - 频繁加锁 / 自旋锁导致线程竞争消耗 CPU。
- 高频率日志打印、无效计算。
- 死循环 / 无限递归(如
- JVM 层面
- 频繁 GC:堆内存过小或内存泄漏导致频繁 Full GC。
- JIT 编译 / 类加载过多:应用启动初期或动态代理场景可能带来短时 CPU 飙升。
- 系统层面
- 大量线程上下文切换。
- 外部依赖阻塞(如网络抖动),导致线程忙等消耗 CPU。
# 3.3 排查思路与工具
定位高 CPU 线程
使用
top -Hp <PID>找出 CPU 占用最高的线程(显示的是线程 IDTID)。将十进制
TID转换为十六进制:printf "%x\n" <TID>1
分析线程堆栈
- 使用
jstack <PID> | grep -A 30 <TID_in_hex>查看对应线程的堆栈。 - 常见现象:
- 无限循环:线程停留在某个方法内反复执行。
- 锁竞争:大量
BLOCKED或WAITING线程。 - GC 线程:
GC Thread占用过高。
- 使用
进一步定位问题
- 使用 Arthas 或 BTrace 动态跟踪方法调用和执行耗时。
- 使用 Java Flight Recorder (JFR) 或 Async-profiler 分析 CPU 火焰图。
# 3.4 解决方案
- 代码问题
- 优化算法,避免死循环 / 空轮询,合理加锁。
- 使用异步 / 批处理代替高频率小任务提交。
- JVM 问题
- 适当调大堆内存,减少 GC 频率。
- 调整 GC 策略(G1/ZGC)提升效率。
- 系统问题
- 优化线程池配置,避免过多线程导致频繁上下文切换。
- 检查外部依赖(数据库、缓存、网络)的超时与重试机制。
# 4.如何用一块只有10M的内存读取1个G的文件进行频率统计?
# 4.1 核心问题分析
- 文件大小远大于可用内存 → 无法一次性加载整个文件
- 频率统计需要存储元素及其计数 → 内存是否足够取决于元素的基数(唯一元素数量)
# 4.2 两种情况分析
情况一:唯一元素数量小
- 内存足够存下全部计数
- 可以直接 内存内统计:
- 按块读取文件(例如 1~2MB 缓冲区)
- 每读一块就更新 HashMap 或数组里的计数
- 不需要持久化,处理简单高效
示例代码(Java):
Map<String, Integer> freqMap = new HashMap<>();
BufferedReader reader = new BufferedReader(new FileReader("largefile.txt"), 2 * 1024 * 1024);
String line;
while ((line = reader.readLine()) != null) {
freqMap.put(line, freqMap.getOrDefault(line, 0) + 1);
}
reader.close();
2
3
4
5
6
7
情况二:唯一元素数量大
- 内存不足以存下全部计数 → 需要 外部存储或分桶
- 典型方法:
- 分块读取文件,每次统计部分数据
- 分桶/哈希:
- 根据元素哈希值,将元素写入不同临时文件
- 确保每个桶的数据量可以在内存内统计
- 统计每个桶:
- 将桶内元素计数存入 HashMap
- 写入磁盘或直接合并桶内统计结果
- 最终合并:
- 合并所有桶的统计结果得到完整频率
原理:类似 MapReduce 外部统计,保证 内存受限也能处理超大文件
# 5.限流算法:固定窗口 / 滑动窗口 / 令牌桶
# 5.1 固定窗口(Fixed Window)
核心原理:
- 将时间划分为固定大小的窗口(如 1 分钟)
- 每个窗口内统计请求次数,超过上限就拒绝
- 简单易实现,但可能在窗口边界出现“突发峰值”
import java.util.HashMap;
import java.util.Map;
public class FixedWindowRateLimiter {
private static final int MAX_REQUESTS = 10; // 每分钟最大请求数
private static final long WINDOW_SIZE = 60000; // 窗口大小(毫秒)
private final Map<String, Integer> requestCount = new HashMap<>();
private long currentWindow = System.currentTimeMillis() / WINDOW_SIZE;
public synchronized boolean allowRequest(String uid) {
long now = System.currentTimeMillis();
long windowKey = now / WINDOW_SIZE;
if (windowKey != currentWindow) {
requestCount.clear();
currentWindow = windowKey;
}
requestCount.putIfAbsent(uid, 0);
int count = requestCount.get(uid);
if (count < MAX_REQUESTS) {
requestCount.put(uid, count + 1);
return true;
}
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 5.2 滑动窗口(Sliding Window)
核心原理:
- 使用 时间戳队列 记录每次请求时间
- 窗口滑动时,移除过期请求,统计窗口内请求数
- 精确限流,可平滑处理边界突发流量
import java.util.*;
public class SlidingWindowRateLimiter {
private static final int MAX_REQUESTS = 10;
private static final long WINDOW_SIZE_MILLIS = 60000;
private final Map<String, Deque<Long>> userRequests = new HashMap<>();
public synchronized boolean allowRequest(String uid) {
long now = System.currentTimeMillis();
userRequests.putIfAbsent(uid, new LinkedList<>());
Deque<Long> timestamps = userRequests.get(uid);
while (!timestamps.isEmpty() && now - timestamps.peekFirst() >= WINDOW_SIZE_MILLIS) {
timestamps.pollFirst();
}
if (timestamps.size() < MAX_REQUESTS) {
timestamps.addLast(now);
return true;
}
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 5.3 令牌桶(Token Bucket)
核心原理:
- 系统维护固定容量的令牌桶,每次请求消耗一个令牌
- 定期往桶中补充令牌,允许请求以固定速率通过
- 可实现平滑流量控制,允许突发请求(桶中有剩余令牌)
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class TokenBucketRateLimiter {
private static final int MAX_TOKENS = 10;
private static final int REFILL_RATE = 1;
private final ConcurrentHashMap<String, AtomicInteger> userBuckets = new ConcurrentHashMap<>();
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
public TokenBucketRateLimiter() {
scheduler.scheduleAtFixedRate(() -> {
for (String uid : userBuckets.keySet()) {
userBuckets.get(uid).updateAndGet(tokens -> Math.min(MAX_TOKENS, tokens + REFILL_RATE));
}
}, 0, 1000, TimeUnit.MILLISECONDS); // 每秒补充1个令牌
}
public boolean allowRequest(String uid) {
userBuckets.putIfAbsent(uid, new AtomicInteger(MAX_TOKENS));
AtomicInteger tokens = userBuckets.get(uid);
if (tokens.get() > 0) {
tokens.decrementAndGet();
return true;
}
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 5.4 三种限流算法对比
| 算法 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| 固定窗口 | 简单易实现 | 窗口边界可能出现突发 | 请求量波动不大 |
| 滑动窗口 | 精确控制请求数,平滑限流 | 内存消耗略大(存储时间戳) | 需要严格限流场景 |
| 令牌桶 | 支持突发流量、平滑限流 | 需定时任务管理令牌 | 高并发平滑限流,允许突发 |
# 6.如果设计一个秒杀系统
秒杀场景的特点是并发量非常大,但是库存很少,所以核心问题就是要 抗住高并发、防止超卖和重复下单。
在架构上,我会分几层:
- 前端层:页面静态化,静态资源放 CDN,减少回源压力;秒杀开始前加上排队等待和验证码来拦截机器人。
- 接入层:Nginx 或网关做限流和负载均衡,避免请求直接打爆后台。
- 缓存层(Redis):活动开始前把商品信息和库存预热到 Redis,用 Lua 脚本保证库存检查和扣减的原子性;同时通过
SETNX(userId+skuId)防止用户重复下单。 - 消息队列(MQ):扣减成功的请求写入 MQ,走异步下单,这样可以削峰填谷,避免数据库被瞬时流量冲垮。
- 数据库层:订单真正落库时再做一次校验,并通过唯一索引保证幂等。
整体流程就是:用户请求 → 网关限流 → Redis 原子扣减库存 → 成功后写 MQ → 消费者异步创建订单 → 数据库校验落单。
关于秒杀库存的扣减,我们从数据库至上层应用来考虑设计。
1.数据库的字短类型无符号整型,防止库存为0
2.数据库采用悲观锁的方式,用户进行秒杀的时候先select * ... for update 加上悲观锁
3.采用乐观锁的方式,先记录查询的时候时间戳,更改的时候再核对一下。记得设置重试次数,防止cpu空转
4.采用redis先讲秒杀商品的库存加载到redis里面,用lua脚本扣减库存,然后mq异步同步
最后,为了防止超卖和一致性问题,除了 Redis 和 Lua,还需要配合 幂等机制、数据库唯一索引、以及库存回补机制 来保证最终一致。
# 7. 订单超时自动取消如何实现
# 7.1 背景说明
在电商、外卖、秒杀等场景中,订单往往需要设置有效期:
- 用户未在规定时间内支付,订单需要自动取消,释放库存。
- 优惠券到期需要自动作废。
- 限时秒杀、拼团活动需要在活动结束时统一关闭。
核心目标:
- 事件能在超时时间点准确触发。
- 支持大规模并发订单。
- 保证不丢单、不超卖。
# 7.2 实现方案对比
# 方案 1:DelayQueue(Java 自带延时队列)
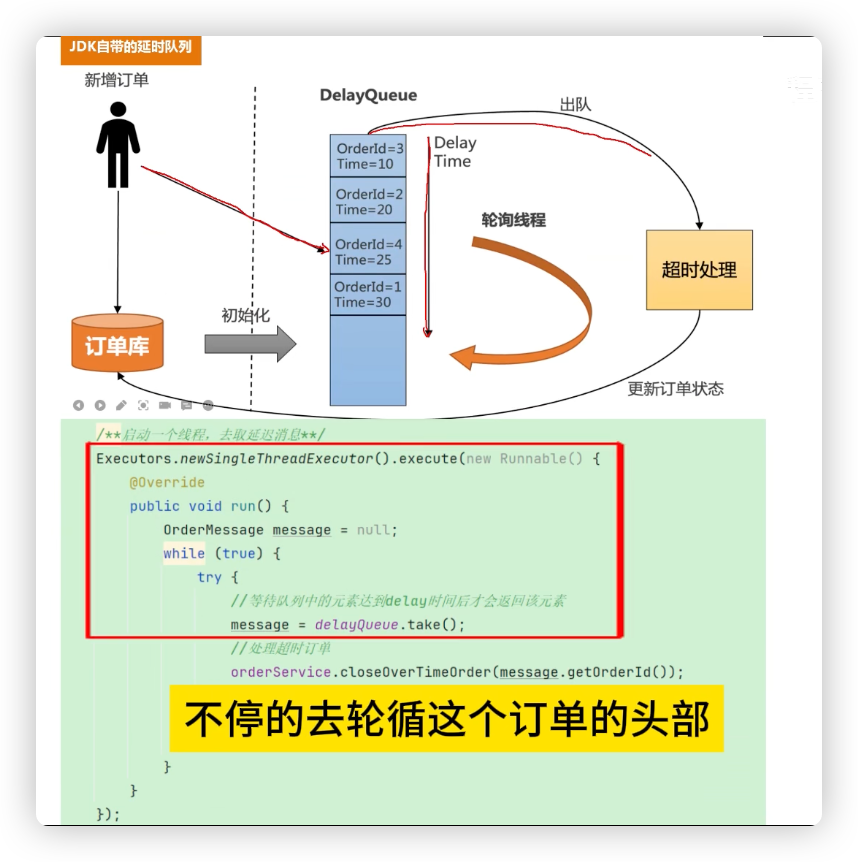
原理:
- 订单创建时,封装成一个延时任务,放入 DelayQueue;
- 消费线程不断轮询队列,取出到期任务,执行取消操作。
优点:
- 简单实现,不依赖第三方中间件;
- 开发成本低,适合 Demo 或小型系统。
缺点:
- 所有订单都要常驻内存,内存占用大;
- 无法分布式扩展,只能在单机或 Leader 节点执行;
- 不适合订单量大、分布式场景。
适用场景:小规模系统,订单量不大。
# 方案 2:RocketMQ 定时/延时消息
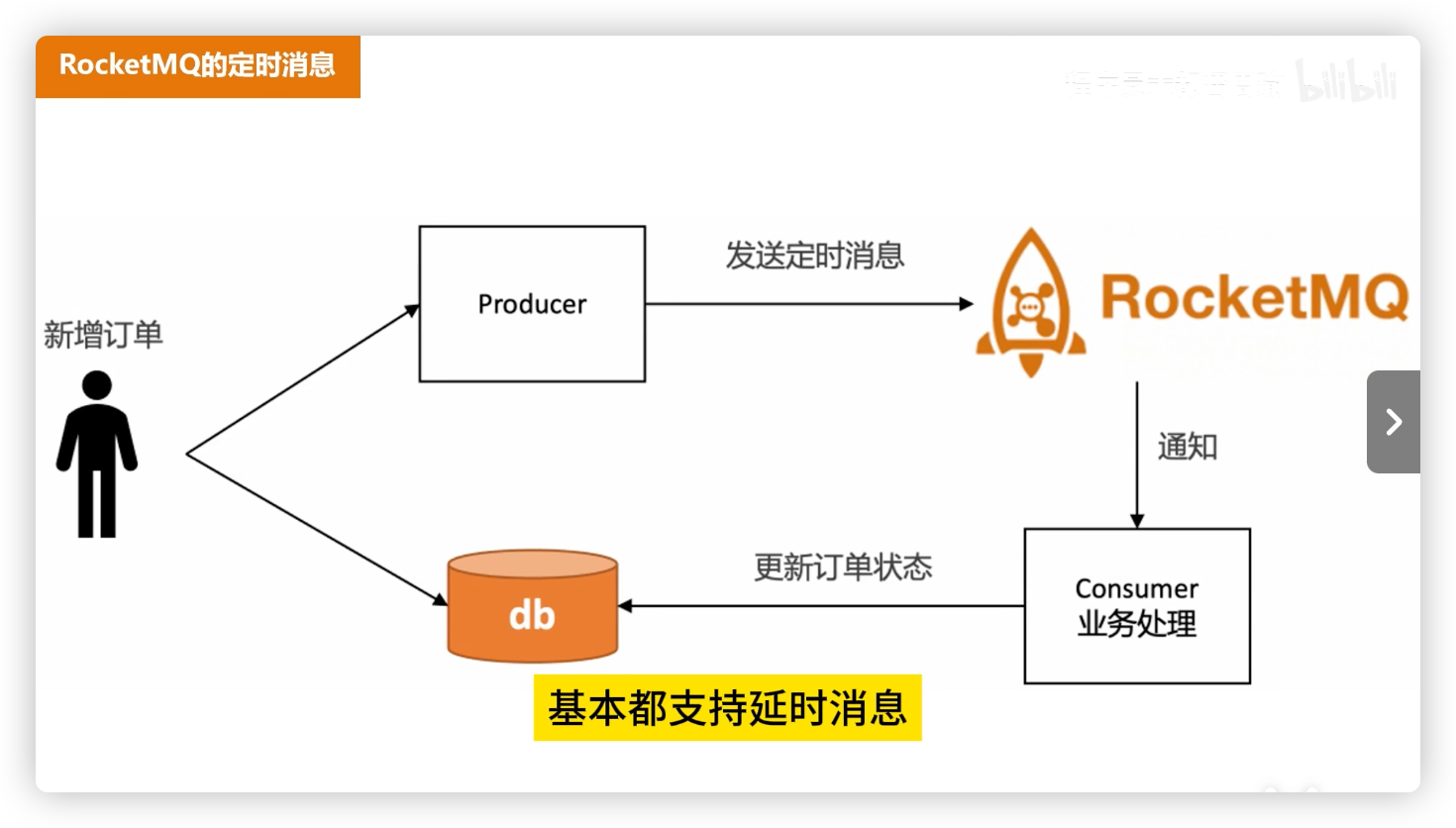
原理:
- 下单时发送一条“延时消息”到 MQ;
- 到期时消息被投递给消费者 → 执行订单关闭逻辑。
优点:
- 使用简单,和普通消息一致;
- 支持分布式;
- 精度较高,可精确到秒。
缺点:
- 时间上限 24 小时(RocketMQ 定时消息的限制);
- 每个订单一条消息,消息堆积会带来较大存储压力;
- 如果同一时间大量消息同时触发,容易形成消费高峰,导致延迟。
适用场景:中等规模订单系统,且超时时间在 24h 内。
# 方案 3:Redis Key 过期监听
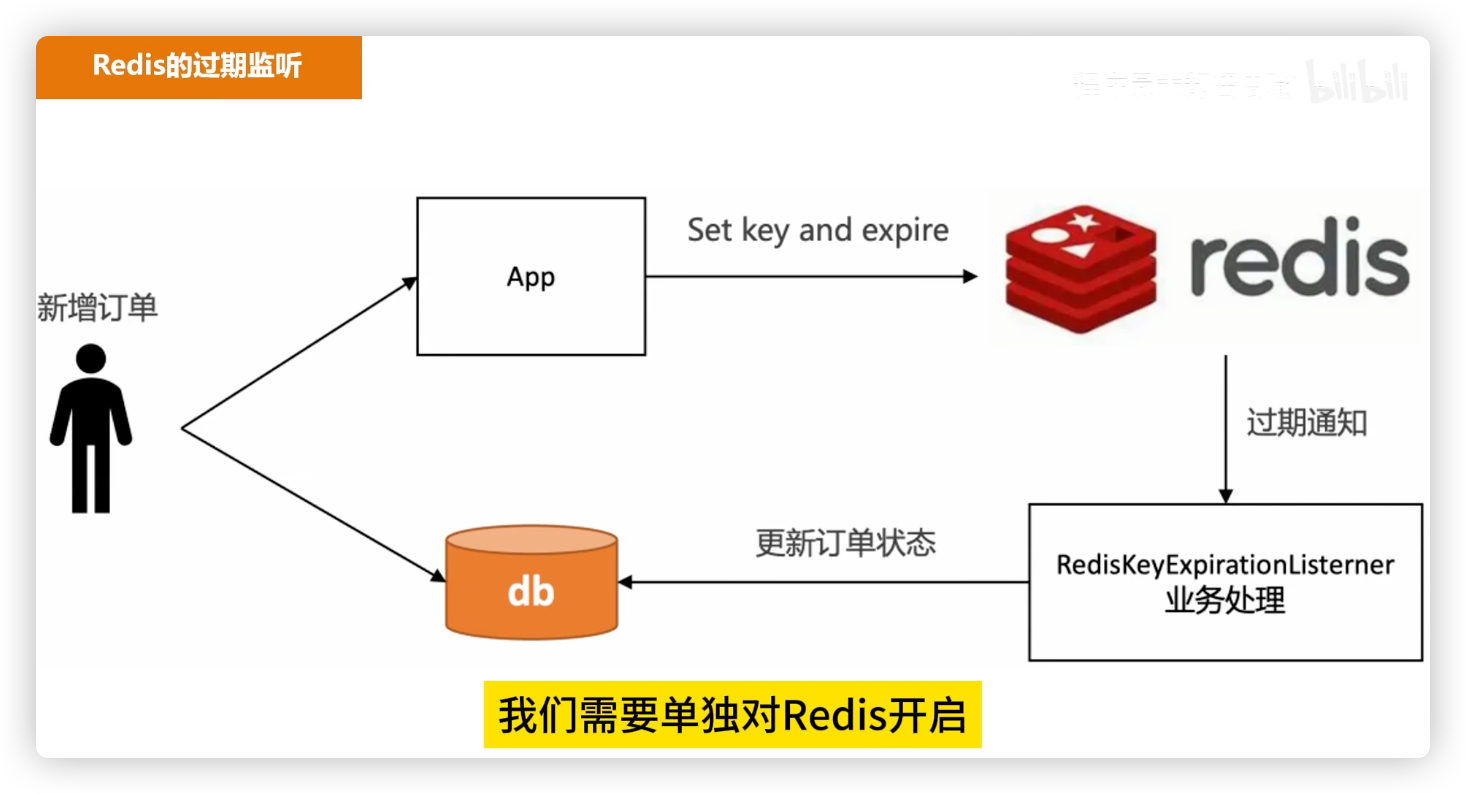
原理:
- 创建订单时设置 Redis Key,过期时间 = 订单超时时间;
- 通过 Redis 过期事件通知,触发订单关闭。
优点:
- 使用简单;
- 延迟精度较高。
缺点:
- 不可靠:Redis 重启或通知丢失 → 订单可能无法关闭;
- 需要额外补偿机制(如定时任务扫库);
- 订单量大时 Redis 内存占用高,增加维护成本。
适用场景:订单量不大 + 有补偿机制的中小型系统。
# 方案 4:定时任务分批处理
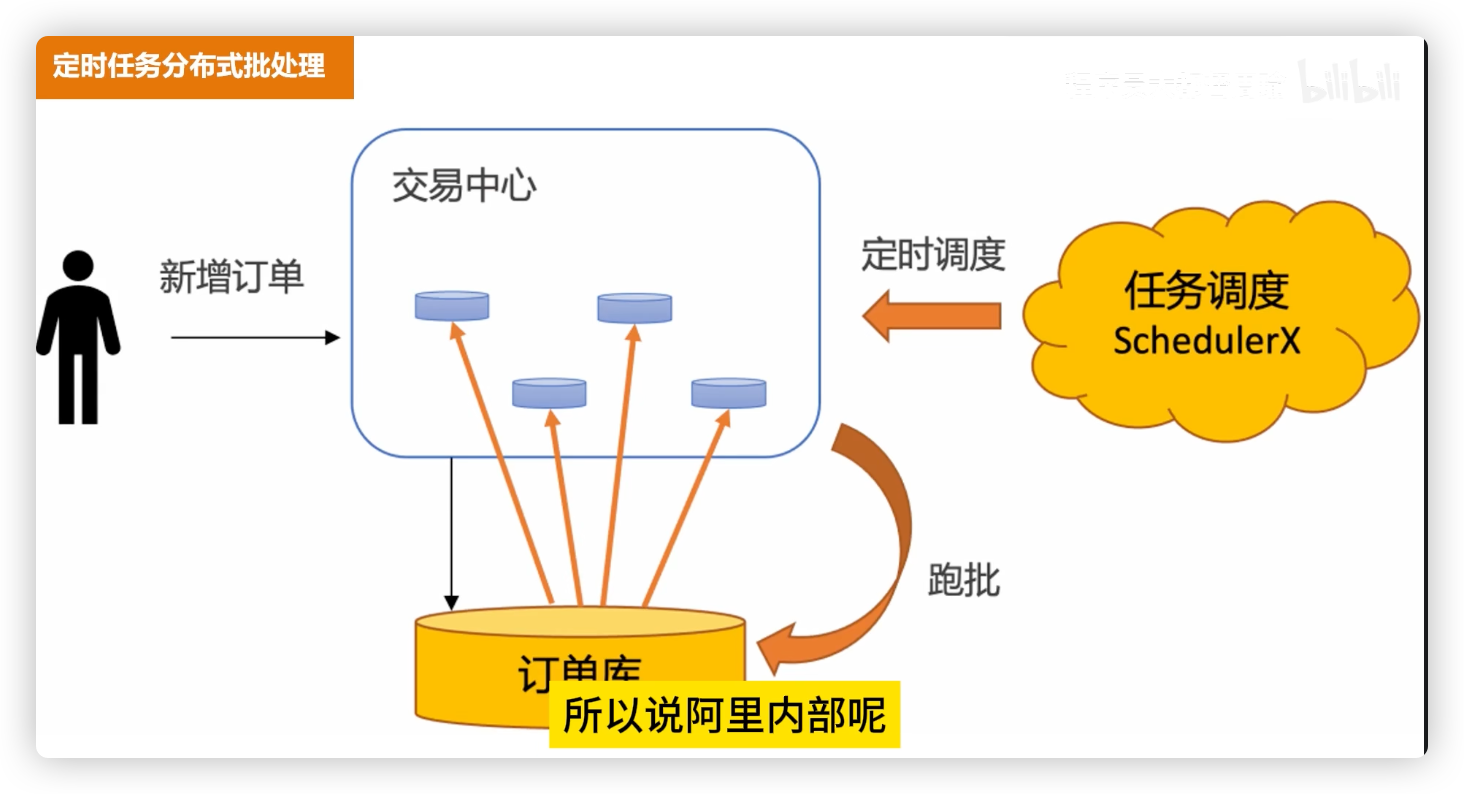
原理:
- 数据库订单表存储“创建时间/过期时间”;
- 定时任务(如 Quartz、xxl-job)定期扫描超时订单,批量关闭。
优点:
- 简单稳定,订单信息集中在数据库;
- 不依赖消息队列、Redis 通知;
- 批量处理,适合大规模订单。
缺点:
- 实时性较差(取决于任务调度间隔,如 1 分钟、5 分钟);
- 高峰期批量更新数据库,可能造成压力。
适用场景:大规模订单系统,允许几分钟级延迟。
# 7.3 方案对比总结
| 方案 | 精度 | 扩展性 | 可靠性 | 适用场景 |
|---|---|---|---|---|
| DelayQueue | 高 | 差 | 一般 | 小型系统 |
| RocketMQ 定时消息 | 高 | 好 | 好 | 中等规模,<24h |
| Redis 过期监听 | 高 | 中 | 一般 | 中小型,需补偿 |
| 定时任务批处理 | 分钟级 | 好 | 高 | 大规模,能容忍延迟 |
# 8.如何防止刷单
防刷单要从 入口限制、过程监控和事后风控 三个层面来做:
- 入口限制
- 登录/注册必须绑定手机号、短信验证码,避免批量注册。
- 对同一个 IP 或设备号限制频率,比如一分钟内最多请求几次。
- 接入验证码(滑动/点选),拦截脚本请求。
- 过程控制
- 对下单接口做 限流和幂等校验,避免短时间内频繁下单。
- 引入 风控规则,比如:同一用户短时间内下多单、同一设备绑定多个账号、异地异常登录等。
- 高风险订单可以进入审核或延迟支付流程。
- 事后风控与大数据分析
- 结合大数据做用户画像,识别羊毛党(频繁薅优惠、异常下单)。
- 建立黑名单系统,对异常账号、设备、IP 段进行封禁。
- 利用机器学习/规则引擎,持续优化风控策略。
总结来说,防止刷单是一个 多层防护体系:前端用验证码 + 限流拦截,后台用幂等校验 + 风控规则,事后再用大数据画像做监控和封禁。
# 9. Redis 大 Key 问题
# 9.1 什么是大 Key(Big Key)?
在 Redis 中,大 Key 并不是指 key 的字符串本身很长,而是指 key 对应的 value 体量过大。常见的几种情况包括:
- 单个 key 的 value 数据量过大(例如一个 string 占用几十 MB)。
- 集合类 key(如 list、set、zset、hash)的成员数量过多(百万甚至千万级)。
- 集合中单个成员数据过大(例如 hash 中某个 field 存储了长文本或大对象)。
# 9.2 大 Key 带来的问题
大 Key 会直接影响 Redis 的性能与稳定性,主要表现在:
- 内存占用过高:导致 Redis 内存紧张,影响其他数据存储。
- 性能下降:访问或操作大 Key 时耗时过长,可能导致请求延迟显著增加。
- 阻塞其他操作:如
DEL、LRANGE、HGETALL等对大 Key 的操作可能阻塞单线程 Redis 主进程,拖慢所有请求。 - 网络阻塞:返回大 Key 时产生大数据包,导致网络传输延迟或阻塞。
- 数据倾斜:在分布式场景(如 Redis Cluster)中,大 Key 可能集中在少数节点,造成负载不均衡。
# 9.3 大 Key 产生的原因
常见原因包括:
- 存储大型数据结构:未经过拆分或序列化压缩的对象直接写入 Redis。
- 缓存滥用:将原本不适合缓存的完整数据结构(如大日志文件、大列表)写入 Redis。
- 应用设计不合理:未对业务数据进行分片,导致热点数据持续堆积在某个 Key 中。
- 数据累计:未设置过期时间或清理机制,数据不断增加。
# 9.4 如何快速定位大 Key?
Redis 提供了一些工具与命令帮助排查:
SCAN 命令:支持渐进式遍历,不会阻塞 Redis 主线程,可用于批量扫描 key,对扫描出来的 key,结合
MEMORY USAGE或集合类命令统计大小:。--bigkeys 参数:在使用
redis-cli时加上--bigkeys参数,可以统计不同数据结构的大 Key 分布情况。redis-cli --bigkeys1Redis RDB Tools:对 RDB 文件进行分析,统计 key 的大小、类型、分布情况。
# 9.5 优化与解决方案
针对大 Key 问题,可以从以下几个角度优化:
- 拆分成小 Key
- 将一个大集合拆分为多个小集合,按业务维度或时间维度切分。
- 例如,将一个存储所有用户数据的 hash,拆分为多个用户 ID 分片存储。
- 优化数据结构
- 根据场景选择合适的 Redis 数据类型,避免存储冗余数据。
- 使用压缩编码(如 ziplist、listpack)或序列化方式减小数据体积。
- 设置合理的过期时间
- 防止数据长期累积,定期清理历史数据。
- 对临时性数据(如会话信息、缓存结果)设置合理 TTL。
- 启用内存淘汰策略
- 在
redis.conf中设置maxmemory-policy,避免内存占满导致 OOM。 - 常用策略有
volatile-lru、allkeys-lru等。
- 在
- 数据分片
- 在 Redis Cluster 或分布式场景下,将数据按业务维度打散,避免数据倾斜。
- 删除大 Key
- 对历史遗留大 Key,采用
UNLINK(异步删除)替代DEL,避免阻塞。 - 对集合类大 Key,可以分批删除子元素,避免一次性清理导致卡顿。
- 对历史遗留大 Key,采用
- 增加内存容量
- 在硬件允许的情况下,适当增加 Redis 实例内存,缓解大 Key 占用问题。
# 10.大文件断点上传如何实现
大文件断点上传(resumable upload)通常的实现思路是 分片上传 + 断点记录 + 校验与合并。可以分成以下几个步骤:
- 文件切片(Chunking)
- 将大文件在客户端按固定大小(如 2MB、5MB)切分为多个小块(chunk)。
- 每个分片单独计算 唯一标识(如 MD5 哈希),用于校验完整性和避免重复上传。
- 上传控制(Upload Control)
- 客户端在上传前先向服务端请求,传递文件的全局唯一 ID(如文件 MD5 + 文件名)。
- 服务端检查是否已经上传过部分分片,返回已上传的分片列表。
- 断点续传(Resume Upload)
- 客户端只上传未完成的分片。
- 上传过程中如果中断,下次继续时先查询已完成的分片,再从断点续传。
- 分片合并(Merge Chunks)
- 服务端接收完所有分片后,按顺序将它们合并成完整文件。
- 合并后可再进行一次 整体文件校验(如 MD5/SHA256),确保文件完整性。
- 优化点
- 并发上传:多个分片同时上传,加快速度。
- 秒传:如果服务端检测到文件已存在(MD5 相同),则直接返回成功,不再上传。
- 失败重传:对失败的分片单独重试,而不是重新传整个文件。
简洁面试版回答:
你可以回答:
大文件断点上传一般通过分片上传实现。首先客户端把大文件切分成固定大小的分片,并计算文件的唯一标识(比如 MD5)。上传时先询问服务端,获取哪些分片已经上传过。客户端只上传缺失的分片,上传过程中支持并发上传和失败重传。服务端保存分片并记录进度,所有分片上传完成后再进行合并和完整性校验。这样可以保证中断后续传,并避免重复上传。
当客户端上传一个分片时:
Content-Length告诉服务端 这块有多大;Content-Range告诉服务端 这块属于整个文件的哪一段。这样,服务端就能正确接收并把分片拼接起来,支持 断点续传
# 11.在你的项目中你用到了哪些设计模式?
首先是工厂方法模式。
我定义了 SpringAiChatModelFactory 作为抽象工厂接口,每个 AI 平台(例如 OpenAI、Ollama)都有各自的具体工厂实现类(如 OpenAiChatModelFactory)。这些工厂类只负责创建对应平台的 ChatModel 实例,从而将对象的创建逻辑与业务逻辑彻底分离。客户端不需要了解 OpenAiChatModel 或 OllamaChatModel 的构造细节,只需依赖工厂接口即可获得正确的实例,实现了良好的解耦与扩展性。
其次是策略模式。
由于不同平台的模型初始化方式并不相同(例如 OpenAI 需要处理 API Key 和代理配置,而 Ollama 则需要 WebClient 的本地模型服务配置),我们将这些差异抽象为一组“策略”,统一由 SpringAiChatModelFactory 接口约束。SpringAiChatModelFactoryManager 作为策略上下文,负责管理所有平台的工厂策略。当需要创建模型时,管理器会根据传入的平台名称自动选择对应的工厂策略,实现了模型创建逻辑的动态切换。这样不仅避免了大量的 if-else 判断,也使扩展新平台时只需要新增一个工厂策略类,无需修改现有代码,符合开闭原则。
最后是单例模式。
得益于 Spring 框架,所有工厂类都通过 @Service 注册为单例 Bean。SpringAiChatModelFactoryManager 在启动时通过构造器一次性注入所有工厂实例,保证它们在系统中全局唯一。这种单例式的管理不仅减少了对象创建带来的开销,也确保了模型初始化行为的一致性和稳定性。