 Java集合框架
Java集合框架
# Java集合框架
集合这东西啊,在咱们开发里简直是“万金油”,ArrayList、LinkedList、HashMap、HashSet,随随便便就能掏出来用,IDE里敲几下键盘,代码就哗哗往外冒,效率拉满!不过呢,光会用可不行,咱们得做个有追求的码农,对吧?要是能搞清楚这些API背后是怎么玩儿的,原理是什么,就像自带“显微镜”一样,把集合的“内脏”看得清清楚楚,那感觉多带劲儿啊!这可不是简单地用工具,而是咱们在驾驭工具,想怎么玩就怎么玩,牛不牛?
# 1. 集合框架是个啥?先来个全家福!
Java集合框架(Java Collections Framework,简称JCF)是Java提供的一套“工具箱”,专门用来装和管理对象。它从Java 1.2开始崭露头角,彻底告别了早期数组、Vector那种“各自为战”的混乱局面。集合框架的核心就是两大“门派”:Collection和Map,加上它们的“徒子徒孙”,组成了一个超级大家庭。
想象一下,集合框架就像一个大超市:
Collection:货架上放着一堆单品,比如List(有序可重复)、Set(无序不可重复)、Queue(队列操作)。Map:货架上摆的是“键值对”套装,靠key找value,简单粗暴。
下图是集合框架的“全家福”,有点眼花缭乱?别慌,咱们一步步拆开聊!
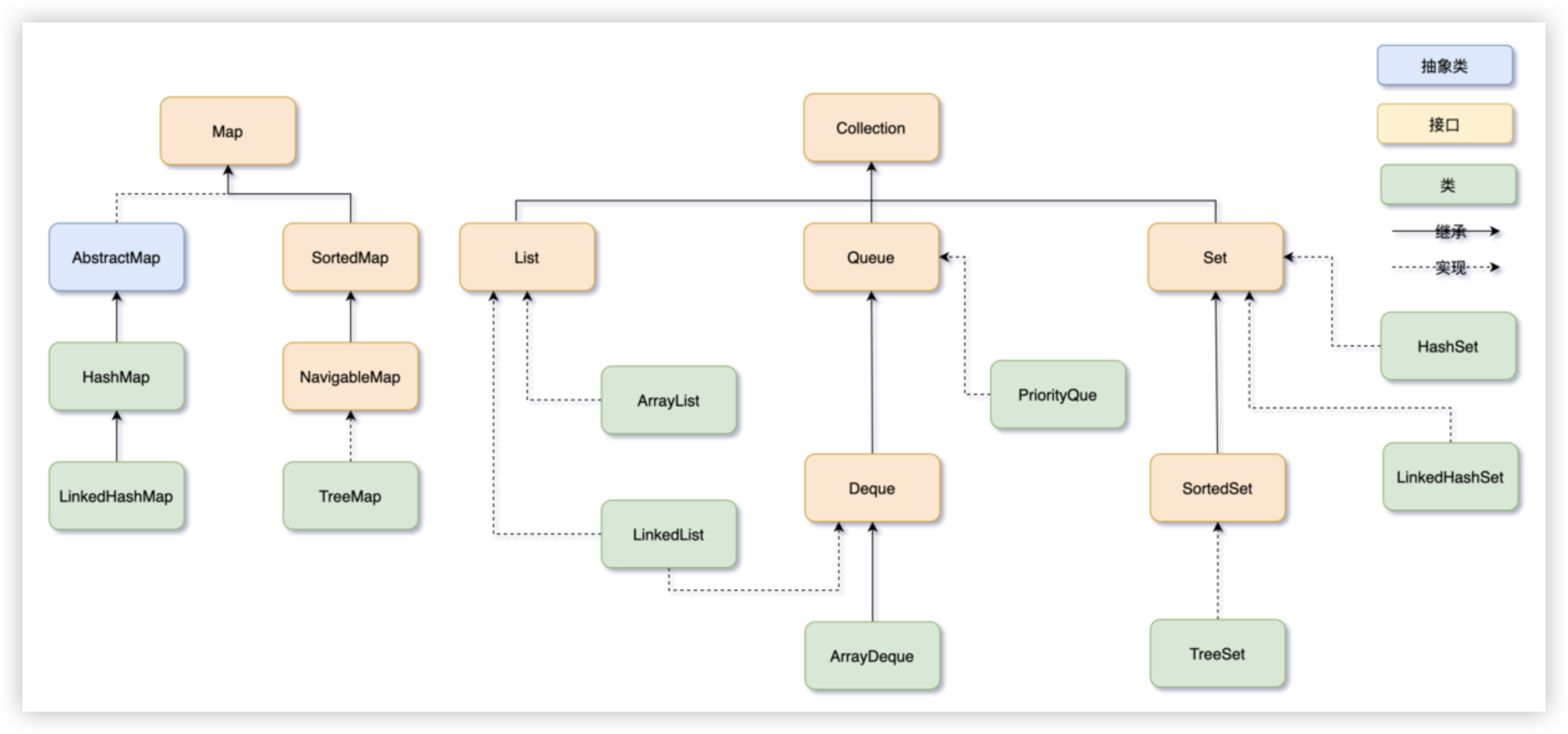
# 2. 两大门派,带你认亲戚
# 2.1 Collection——单身贵族的天下
Collection是所有单元素集合的“老祖宗”,它定义了增删改查的基本套路。它的三大分支各有绝技:
List:有序、可重复,像个记性超好的管家,按顺序摆好东西,常见选手有ArrayList(数组快查)和LinkedList(链表快改)。Set:无序、不重复,像个“洁癖患者”,绝不允许俩长一样的家伙混进来,代表有HashSet(哈希表)和TreeSet(有序树)。Queue:队列选手,讲究“先进先出”或“优先级”,比如PriorityQueue(优先级堆)和ArrayDeque(双端数组)。
# 2.2 Map——键值对的王者
Map不归Collection管,它专管键值对<key, value>,通过key定位value,key绝不重复。它的明星成员有:
HashMap:哈希表扛把子,查找快到飞起。TreeMap:红黑树高手,自带排序功能。LinkedHashMap:哈希表加链表,能记插入顺序还能玩LRU。
# 3. 工具侠——Iterator和朋友们
集合再牛,也得会“翻箱倒柜”找东西吧?这时候,遍历工具就上场了:
Iterator:单向遍历老大哥,能看(next())、问(hasNext())、删(remove())。Iterable:Iterator的“升级版外壳”,支持增强for循环(Java 1.8起还加了forEach),底层还是靠Iterator干活。ListIterator:List专属,双向遍历+任意起点,简直是“灵活小王子”。
# 3.1 Iterator接口
源码:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
2
3
4
5
提供的API接口含义如下:
hasNext():判断集合中是否存在下一个对象next():返回集合中的下一个对象,并将访问指针移动一位remove():删除集合中调用next()方法返回的对象
在早期,遍历集合的方式只有一种,通过Iterator迭代器操作
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator iter = list.iterator();
while (iter.hasNext()) {
Integer next = iter.next();
System.out.println(next);
if (next == 2) { iter.remove(); }
}
2
3
4
5
6
7
8
9
10
# 3.2 Iterable 接口
源码:
public interface Iterable<T> {
Iterator<T> iterator();
// JDK 1.8
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
2
3
4
5
6
7
8
9
10
- 特点:提供了
Iterator接口,实现了Iterable的集合都能用迭代器遍历。 - 新技能:JDK 1.8加入
forEach(),支持增强for循环。
用法:
List<Integer> list = new ArrayList<>();
for (Integer num : list) {
System.out.println(num);
}
2
3
4
真相:用javap -c反编译,发现增强for是语法糖,等价于:
Iterator<Integer> iter = list.iterator();
while (iter.hasNext()) {
Integer num = iter.next();
System.out.println(num);
}
2
3
4
5
# 3.3 ListIterator接口
还没完!ListIterator登场,它继承Iterator,专为List打造,支持任意起点和双向遍历。
用法:
List<Integer> list = new ArrayList<>();
ListIterator<Integer> listIter1 = list.listIterator(); // 从0开始
ListIterator<Integer> listIter2 = list.listIterator(5); // 从5开始
2
3
源码:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e); // 替换最后访问的元素
void add(E e); // 在当前位置插入
}
2
3
4
5
6
7
8
9
10
11
- 升级点:比
Iterator多出回退(previous)、索引感知(nextIndex/previousIndex)、修改(set/add)。 - 特点:从任意下标起跳,双向操作,功能更强。
# 4. Map家族——键值对界的扛把子
# 4.1 HashMap:快枪手
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
- 绝技:哈希表(数组+链表+红黑树),查找和插入平均O(1)。
- 特点:无序、非线程安全,冲突多时链表变红黑树(长度>8且数组>64)。
- 用法:随便存键值对,速度第一选择。
HashMap<String, Integer> map = new HashMap<>();
map.put("苹果", 5);
map.put("香蕉", 3);
System.out.println(map.get("苹果")); // 输出5
2
3
4
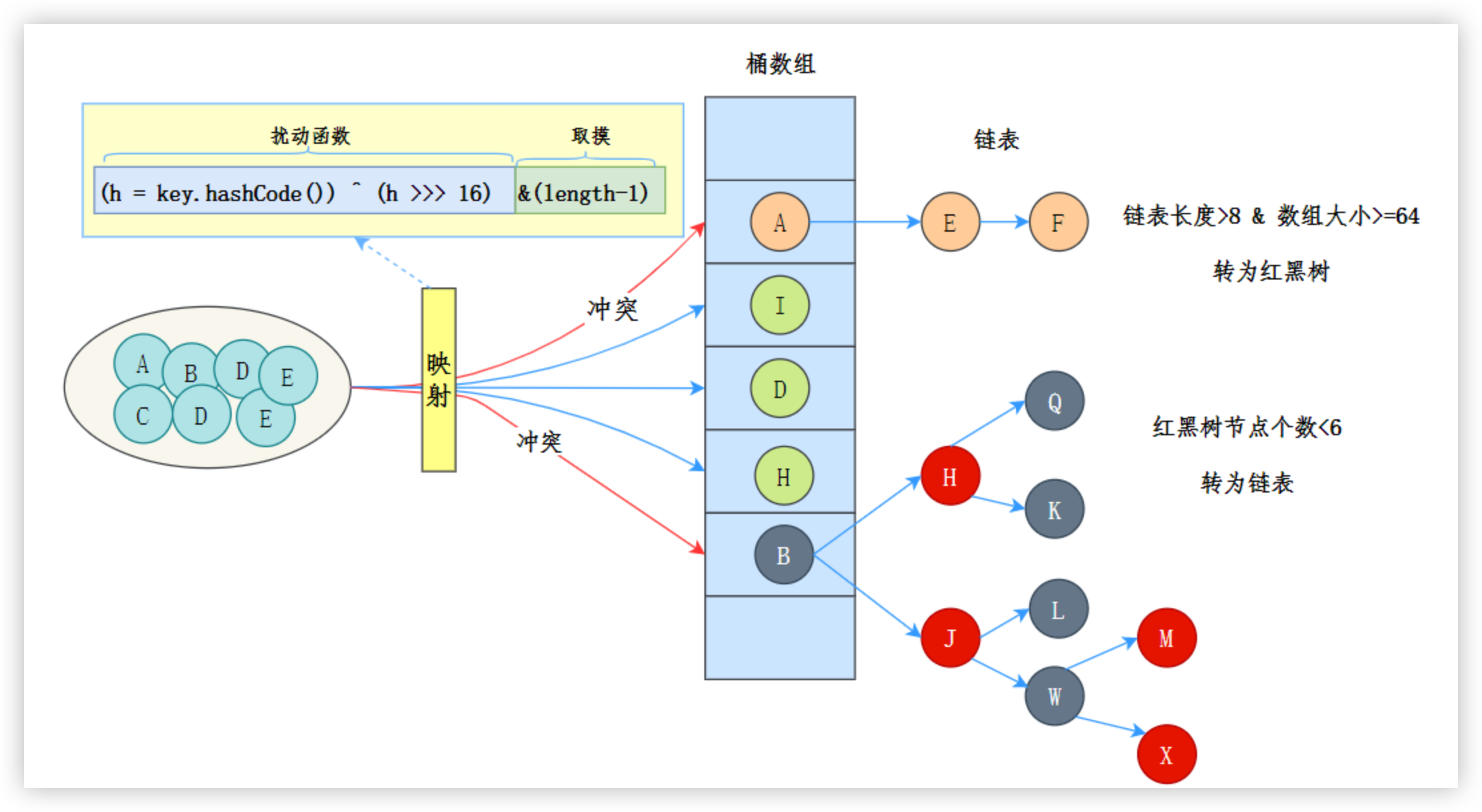
HashMap 的存储过程基于哈希表,通过键的哈希码计算存储位置。主要步骤如下:
- 计算哈希码: 调用键的
hashCode()方法,得到一个整数。 - 确定桶位置: 用哈希码通过哈希函数(如
(n - 1) & hash)计算数组索引。 - 处理碰撞: 如果桶内已有元素,使用链表或红黑树存储新键值对。
- 存储键值对: 将键值对放入对应桶,必要时扩容数组。
从 Java 8 开始,当桶内元素过多时,链表会转为红黑树以优化查找效率。
存储过程:
# 1. 计算键的哈希码
- 过程: 当调用
put(K key, V value)时,HashMap 首先通过键的hashCode()方法获取一个整数哈希码。 - 细节:
hashCode()是 Object 类的方法,用户可以自定义。如果键是 null,哈希码定义为 0。 - 优化: HashMap 内部通过一个额外的扰动函数(
hash()方法)优化哈希码,减少碰撞:这里将哈希码高 16 位与低 16 位异或,确保高位信息参与索引计算,降低碰撞概率。static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }1
2
3
4
# 2. 确定桶的位置
- 过程: 使用哈希码计算键值对在数组中的存储位置(桶索引)。
- 底层结构: HashMap 使用一个
Node<K,V>[]数组(称为 table)存储数据,每个数组元素是一个桶。 - 哈希函数: 桶索引通过
(n - 1) & hash计算,其中:n是数组长度(总是 2 的幂,如 16、32)。hash是优化后的哈希码。
- 为什么用 &: 因为
n是 2 的幂,(n - 1)的二进制全是 1,&操作相当于取模运算(hash % n),但效率更高。 - 示例:
- 假设数组长度为 16,哈希码为 20。
(n - 1) = 15,二进制为1111。20 & 15 = 4,键值对存储在索引 4 的桶中。
# 3. 处理碰撞
场景: 如果多个键的哈希码映射到同一索引(即碰撞),需要解决冲突。
Java 7 及之前: 使用链表。
- 桶内已有元素时,新键值对作为链表节点插入(头插法)。
- 查找时间复杂度为 O(n),n 是链表长度。
Java 8 改进: 链表 + 红黑树。
- 当桶内元素少于 8 时,使用链表。
- 当链表长度超过 8 且数组长度至少为 64 时,转换为红黑树。
- 红黑树查找时间复杂度为 O(log n),优化了大量碰撞时的性能。
Node 内部类:
static class Node<k,v> implements Map.Entry<k,v> { final int hash; final K key; V value; Node<K,V> next; }1
2
3
4
5
6TreeNode 内部类
红黑树使用
TreeNode类,继承LinkedHashMap.Entry<k,v>并增加了树结构相关字段,其实你会发现他的父类也是继承了Map.Entry<k,v>。static final class TreeNode<k,v> extends LinkedHashMap.Entry<k,v> { TreeNode<k,v> parent; // 父节点 TreeNode<k,v> left; //左子树 TreeNode<k,v> right;//右子树 TreeNode<k,v> prev; // needed to unlink next upon deletion boolean red; //颜色属性 }1
2
3
4
5
6
7桶位
HashMap类中有一个非常重要的字段,就是
Node[] table,即哈希桶数组,明显它是一个Node的数组。transient Node<k,v>[] table;//存储(位桶)的数组1
# 4. 存储键值对
- 过程: 将键值对封装为 Node 或 TreeNode 对象,放入对应桶。
- 扩容检查: 每次 put 后,检查元素数量是否超过阈值(
threshold = capacity * loadFactor)。- 默认容量(capacity)为 16,加载因子(loadFactor)为 0.75。
- 若超过阈值,数组扩容为原先两倍(例如 16 -> 32)。
- 扩容后,所有元素重新计算索引并迁移(rehash),因为数组长度变化影响
(n - 1) & hash的结果。
# 存储过程示例
假设初始 HashMap 容量为 16,加载因子 0.75,存储键值对 ("key1", "value1"):
- 调用
key1.hashCode(),假设返回 12345。 - 扰动计算:
12345 ^ (12345 >>> 16),得到优化哈希码,例如 12350。 - 计算索引:
(16 - 1) & 12350 = 15 & 12350 = 14。 - 检查 table[14]:
- 若为空,创建新 Node,放入 table[14]。
- 若不为空,插入链表或红黑树。
- 元素数量加 1,检查是否需要扩容。
源码分析:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 定义节点数组和临时节点变量
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
// 如果哈希表为空或长度为0,进行初始化(扩容)
// 通过resize()方法创建或扩展哈希表,并获取新的表长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算插入位置的索引,使用哈希值与表长度-1按位与运算
// 如果该位置为空,直接创建新节点并放入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 该位置已有节点,需要处理哈希冲突
Node<K,V> e;
K k;
// 情况1:如果首节点的哈希值和键完全匹配,直接找到该节点
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 情况2:如果是红黑树节点,使用红黑树的插入方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 情况3:链表节点,遍历链表寻找插入位置
else {
for (int binCount = 0; ; ++binCount) {
// 如果到达链表末尾,创建新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表长度达到转换阈值,尝试将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 如果找到相同的键,退出循环
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
// 移动到下一个节点
p = e;
}
}
// 如果找到已存在的键
if (e != null) {
V oldValue = e.value;
// 根据参数决定是否更新值
// onlyIfAbsent为true时,仅在原值为null时才更新
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 调用钩子方法,用于子类扩展
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 修改次数+1
++modCount;
// 判断是否需要扩容
if (++size > threshold)
resize();
// 调用插入后的钩子方法
afterNodeInsertion(evict);
// 对于新插入的键值对,返回null
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
# 关键细节
- null 键处理: null 键的哈希码为 0,通常存储在 table[0]。
- 扩容代价: 扩容涉及数组复制和 rehash,时间复杂度为 O(n),可能影响性能。
- 红黑树转换条件:
- 链表长度 ≥ 8(
TREEIFY_THRESHOLD)。 - 数组长度 ≥ 64(
MIN_TREEIFY_CAPACITY)。 - 若数组长度小于 64,仅扩容,不转为树。
- 链表长度 ≥ 8(
# 4.2 LinkedHashMap:记性好
- 绝技:HashMap+双向链表,默认记插入顺序,设
accessOrder=true还能按访问顺序排(LRU神器)。 - 用法:需要顺序或缓存时用它。
LinkedHashMap<String, Integer> lmap = new LinkedHashMap<>(16, 0.75f, true);
lmap.put("A", 1);
lmap.put("B", 2);
lmap.get("A"); // 访问A,顺序变为B->A
2
3
4
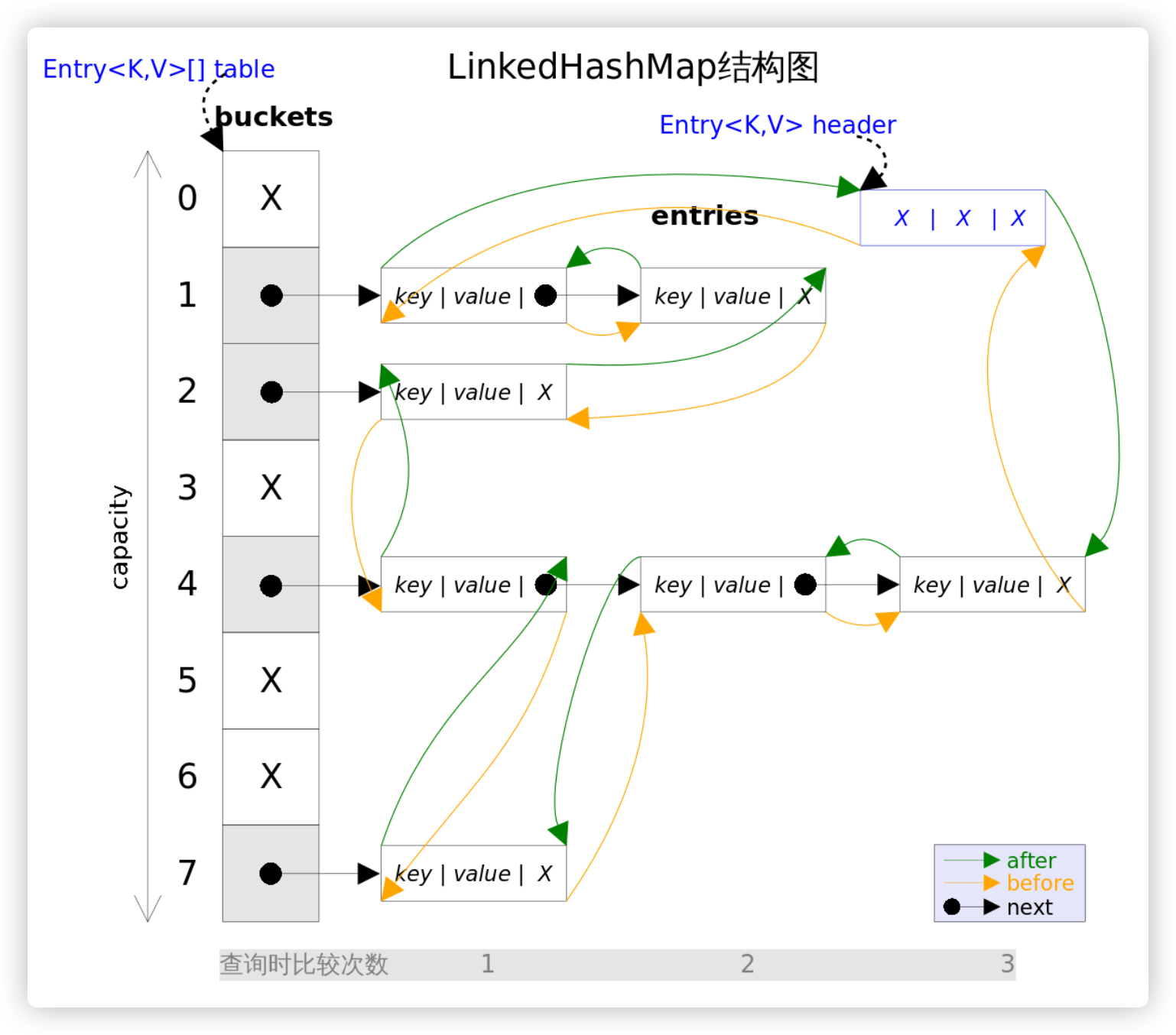
# 1. 底层结构变化
- LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements SequencedMap<K,V>
{
//
}
2
3
4
5
6
- LinkedHashMap在父类的基础上新增了3个重要属性
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: {@code true}
* for access-order, {@code false} for insertion-order.
*
* @serial
*/
final boolean accessOrder;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 这里用的节点是
Entry,before、After是用于维护Entry插入的先后顺序的
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2
3
4
5
6
7
8
9
# 2.构造方法变化
不过新的JDK版本已经不使用这种方法了,是在插入元素的时候来判断,进行创建,这里也提一下老版本
public static void main(String[] args) {
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}
2
3
4
5
构造过程解析
LinkedHashMap 继承自 HashMap,其构造方法会调用父类 HashMap 的构造方法,创建存储数据的 table 数组。
public LinkedHashMap() {
super();
accessOrder = false;
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
2
3
4
5
6
7
8
9
10
LinkedHashMap 重写了 init() 方法,在调用父类构造方法后,初始化一个双向链表的头结点 header。
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
2
3
4
此 header 并不存储数据,而是作为链表头尾的标志。
# 3. 存储过程变化
LinkedHashMap 并未重写 HashMap 的 put() 方法,而是重写了几个个函数其中插入节点newNode(int hash, K key, V value, Node<K,V> e) 和一些钩子函数用于LRU: afterNodeAccess(evict) 和 afterNodeInsertion(evict)和afterNodeRemoval(evict),实现双向链表维护插入顺序。
这段代码是 Java 中 LinkedHashMap 的三个关键方法,它们分别处理节点的插入、移除和访问时的特殊行为。让我详细解释:
afterNodeInsertion(boolean evict)方法:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
void afterNodeInsertion(boolean evict) {
// 可能移除最老的条目
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
2
3
4
5
6
7
8
9
10
11
- 这个方法主要用于实现 LRU(最近最少使用)缓存策略
- 当
evict为 true 且头节点存在时,会调用removeEldestEntry()方法,这里其实LinkedHashMap默认是不移除的,我们想要实现自动清理最老元素需要手动去实现。见下面代码案例 - 如果
removeEldestEntry()返回 true,则会移除最老(最先插入)的节点 - 通常用于控制 LinkedHashMap 的大小,比如限制缓存的最大条目数
afterNodeRemoval(Node<K,V> e)方法:
void afterNodeRemoval(Node<K,V> e) {
// 解除链接
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e,
b = p.before,
a = p.after;
p.before = p.after = null;
// 调整头指针
if (b == null)
head = a;
else
b.after = a;
// 调整尾指针
if (a == null)
tail = b;
else
a.before = b;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 当一个节点被移除时,需要调整双向链表的连接
before和after是维护插入顺序的双向链表指针- 确保移除节点后,链表的前后连接正确
afterNodeAccess(Node<K,V> e)方法:
void afterNodeAccess(Node<K,V> e) {
// 根据不同的模式处理节点访问
LinkedHashMap.Entry<K,V> last;
LinkedHashMap.Entry<K,V> first;
// 将节点移动到链表末尾(按最近使用排序)
if ((putMode == PUT_LAST || (putMode == PUT_NORM && accessOrder))
&& (last = tail) != e) {
// 移动节点到末尾的复杂逻辑
// ...
}
// 将节点移动到链表开头
else if (putMode == PUT_FIRST && (first = head) != e) {
// 移动节点到开头的复杂逻辑
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 这个方法处理节点访问时的排序逻辑
- 支持两种主要模式:
- 按插入顺序保存(默认)
- 按访问顺序排序(
accessOrder = true)
- 当节点被访问时,可以将其移动到链表末尾或开头
这三个方法共同实现了 LinkedHashMap 的核心特性:
- 维护插入顺序
- 支持 LRU 缓存策略
- 提供灵活的节点访问和排序机制
举个例子,如果你创建 LinkedHashMap 并设置 accessOrder 为 true:
Map<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true);
map.put("A", 1);
map.put("B", 2);
map.get("A"); // 这会将 "A" 移动到链表末尾
2
3
4
这种设计使得 LinkedHashMap 既可以作为普通有序映射,也可以作为高效的缓存容器。
# 4. 读取元素过程
LinkedHashMap 重写了 get() 方法,当 accessOrder 为 true 时,每次访问都会调整链表顺序。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
2
3
4
5
6
7
8
afterNodeAccess() 负责将最近访问的元素移至链表尾部。
# 5. 实现 LRU 缓存
LinkedHashMap 可用于 LRU 缓存,只需设置 accessOrder=true 并重写 removeEldestEntry()。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int maxSize;
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
LRU 访问示例
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<>(3);
cache.put("A", "1");
cache.put("B", "2");
cache.put("C", "3");
System.out.println(cache.keySet()); // [A, B, C]
cache.get("A");
cache.put("D", "4");
System.out.println(cache.keySet()); // [C, A, D]
}
2
3
4
5
6
7
8
9
10
# 4.3 TreeMap:排序大师
- 绝技:红黑树实现,O(log n),键天然有序(或自定义Comparator,初始化为0,插入元素的时候创建head)。
- 用法:需要键排序时,比如排行榜。
TreeMap<Integer, String> tmap = new TreeMap<>();
tmap.put(3, "三");
tmap.put(1, "一");
System.out.println(tmap); // {1=一, 3=三}
2
3
4
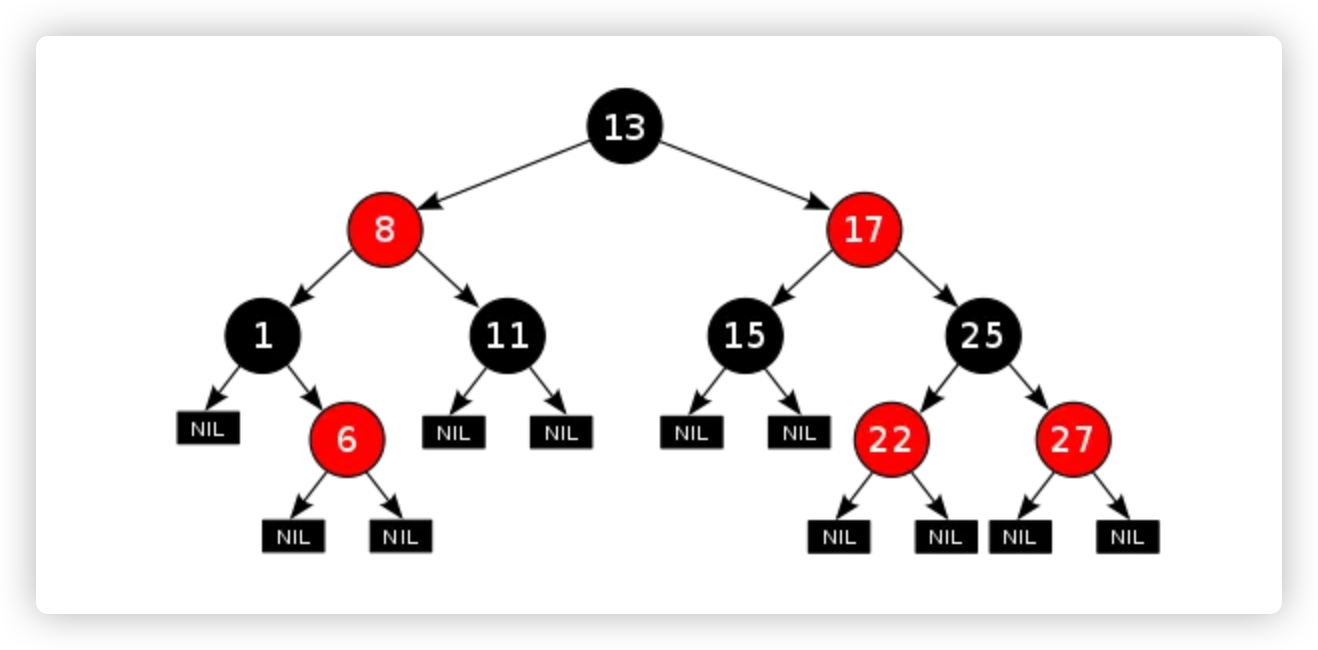
# 1. 底层结构
- TreeMap基于红黑树实现,继承自AbstractMap,实现NavigableMap接口
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
// 红黑树的根节点
private transient Entry<K,V> root;
// 树中元素数量
private transient int size = 0;
// 比较器,决定元素排序
private final Comparator<? super K> comparator;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 2. 核心节点结构
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left; // 左子树
Entry<K,V> right; // 右子树
Entry<K,V> parent; // 父节点
boolean color = BLACK; // 节点颜色
}
2
3
4
5
6
7
8
# 3. 构造方法
// 默认构造:使用自然排序
public TreeMap() {
comparator = null;
}
// 自定义比较器构造
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2
3
4
5
6
7
8
9
# 4. 插入过程(put方法)
public V put(K key, V value) {
// 找到插入的父节点位置
Entry<K,V> t = root;
if (t == null) {
// 空树直接创建根节点
root = new Entry<>(key, value, null);
size = 1;
return null;
}
// 比较找到合适的插入位置
int cmp;
Entry<K,V> parent;
do {
parent = t;
cmp = compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value); // 键已存在,更新值
} while (t != null);
// 创建新节点并插入
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 修复红黑树平衡
fixAfterInsertion(e);
size++;
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 5. 红黑树平衡算法(fixAfterInsertion)
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED; // 新节点标记为红色
while (x != null && x != root && x.parent.color == RED) {
// 复杂的旋转和重新着色逻辑
// 保证红黑树的五大性质
}
root.color = BLACK; // 根节点必须是黑色
}
2
3
4
5
6
7
8
9
10
# 6. 查找过程(get方法)
public V get(Object key) {
Entry<K, V> p = getEntry(key);
return (p == null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
if (comparator != null)
return getEntryUsingComparator(key);
// 使用comparable进行比较
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 7. 特色方法
// 获取最小键
public K firstKey() {
return key(getFirstEntry());
}
// 获取最大键
public K lastKey() {
return key(getLastEntry());
}
// 范围查询
public SortedMap<K,V> subMap(K fromKey, K toKey) {
return new SubMap(fromKey, toKey);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 8. 性能特点
- 插入、删除、查找:O(log n)
- 有序遍历:O(n)
- 空间复杂度:O(n)
# 9. 使用建议
// 推荐写法
TreeMap<String, Integer> map = new TreeMap<>((a, b) -> b.compareTo(a));
// 降序排列
2
3
小贴士:
- 如果Key实现了Comparable,可直接使用
- 复杂对象建议提供自定义Comparator
- 频繁增删查询的场景首选
# 4.4 WeakHashMap:短命鬼
- 绝技:键是弱引用,GC一来就拜拜,适合临时缓存。
- 用法:存不重要、不常访问的数据。
# 4.5 Hashtable:老前辈
- 绝技:数组 + 链表结构,线程安全(全方法加
synchronized),但性能差,已被淘汰。 - 替代:用
ConcurrentHashMap吧,新时代选择!
# 5.1 Collection家族——单身派对
# 5.2 Set系:不爱重复
# HashSet 源码解析
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// 实际上是包装了一个HashMap
private transient HashMap<E,Object> map;
// 所有元素都用这个共享的Object作为value
private static final Object PRESENT = new Object();
// 构造方法实际是创建HashMap
public HashSet() {
map = new HashMap<>();
}
// 核心:add方法依赖HashMap的put
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 底层完全依赖HashMap
- 元素去重通过HashMap的key唯一性实现
- 时间复杂度O(1)
# LinkedHashSet 源码解析
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E> {
// 构造方法调用父类的特殊构造
public LinkedHashSet() {
super(16, .75f, true);
}
// 实际上调用LinkedHashMap的构造
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 继承自HashSet
- 底层使用LinkedHashMap
- 保持插入顺序
# TreeSet 源码解析
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable {
// 底层是TreeMap
private transient NavigableMap<E,Object> m;
// 构造方法创建TreeMap
public TreeSet() {
this.m = new TreeMap<>();
}
// add方法依赖TreeMap
public boolean add(E e) {
return m.put(e, PRESENT) == null;
}
// 排序实现
public Iterator<E> iterator() {
return m.keySet().iterator();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 底层使用TreeMap
- 元素有序且去重
- 时间复杂度O(log n)
# 5.3 List系:爱排队
# ArrayList 源码解析
在 Java 中,ArrayList 是一个基于动态数组实现的可变长度列表,其默认的初始容量为 10。当 ArrayList 需要扩容时,它的容量会增长为 原容量的 1.5 倍,具体来说,新容量计算方式如下:
newCapacity = oldCapacity + (oldCapacity >> 1);
扩容的核心操作由 Arrays.copyOf() 方法实现,它会创建一个新的数组,并将原数组的内容复制到新数组中,从而避免了手动创建新数组和复制元素的繁琐过程。
优势
- 避免频繁创建新数组
由于ArrayList采用 1.5 倍的扩容策略,而非每次只增加一个元素,因此可以减少扩容次数,提升性能。 - 减少内存碎片
相比 2 倍扩容策略,1.5 倍扩容既能减少内存占用,也能降低因频繁分配大块内存导致的碎片化问题。 - 优化性能
由于扩容涉及数组复制,扩容的次数越多,性能消耗越大。合理的扩容策略可以在空间与性能之间找到平衡。
如果可以预估 ArrayList 可能存储的元素数量,建议提前使用 ensureCapacity(int minCapacity) 方法,手动调整 ArrayList 的容量,以减少扩容带来的性能损耗。例如:
ArrayList<Integer> list = new ArrayList<>();
list.ensureCapacity(1000); // 预分配至少 1000 个元素的存储空间
2
这样可以避免多次扩容带来的开销,提升程序运行效率。
源码解析
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess {
// 核心存储结构
transient Object[] elementData;
// 实际元素数量
private int size;
// 添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 扩容检查
elementData[size++] = e;
return true;
}
// 随机访问
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
// 关键:扩容机制
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 数组实现
- 连续内存空间
- 查询O(1),增删O(n)
# LinkedList 源码解析
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E> {
// 双向链表节点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
// 首尾节点
transient Node<E> first;
transient Node<E> last;
// 添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
// 链接到末尾
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
- 双向链表实现
- 增删O(1),查询O(n)
- 支持双端操作
# 5.5 Queue系:排队大师
# PriorityQueue 源码解析
PriorityQueue 是 基于堆(通常是最小堆)实现的,其底层存储结构是 动态数组。当插入新元素且数组已满时,会进行扩容。

- 初始容量:默认大小为 11(而不是 10,堆的容量通常选择合适的数字,以更好地保持二叉树的平衡性)。
- 扩容策略:对于容量小于 64 的情况,扩容幅度稍大(约 2 倍),避免频繁扩容。超过 64 后,改为 1.5 倍扩容,减少内存占用。
- 扩容方式:调用
Arrays.copyOf()复制原数组到新数组。
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
// 使用数组存储堆
private transient Object[] queue;
// 比较器
private final Comparator<? super E> comparator;
// 入队
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
// 扩容
int i = size;
if (i >= queue.length)
grow(i + 1);
// 上浮操作
siftUp(i, e);
size++;
return true;
}
// 出队:始终弹出最小/最大元素
public E poll() {
if (size == 0)
return null;
// 交换首尾元素
E result = (E) queue[0];
int n = --size;
E x = (E) queue[n];
queue[n] = null;
// 下沉操作
if (n > 0)
siftDown(0, x);
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 堆实现
- 自动排序
- 出队总是最优先元素
# ArrayDeque 源码解析
ArrayDeque 是 基于环形数组 实现的双端队列,因此扩容方式与 ArrayList 略有不同:
- 初始容量:默认大小为 16(如果有初始化大小,自动扩容到比初始化大的最小
2的幂,至于为什么因为他是双端队列可能方便去模幂运算定位)。 - 扩容策略:新容量为 原容量的 2 倍(始终翻倍)。
- 扩容方式:创建新数组,并将旧数组元素重新排列(按队列顺序复制)。
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E> {
// 循环数组
transient Object[] elements;
// 头尾指针
transient int head;
transient int tail;
// 添加元素
public void addFirst(E e) {
elements[head = (head - 1) & (elements.length - 1)] = e;
}
public void addLast(E e) {
elements[tail] = e;
tail = (tail + 1) & (elements.length - 1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 循环数组实现
- 双端操作
- 性能优于LinkedList
小结:
- Set去重原理:利用Map的key唯一性
- List性能权衡:连续vs链式
- Queue排序:堆 or 链表
# 6. 性能PK,谁是王者?
| 集合 | 增删复杂度 | 查询复杂度 | 数据结构 | 线程安全 |
|---|---|---|---|---|
| ArrayList | O(n) | O(1) | 数组 | 否 |
| LinkedList | O(1) | O(n) | 双向链表 | 否 |
| HashSet | O(1) | O(1) | 哈希表+红黑树 | 否 |
| TreeSet | O(log n) | O(log n) | 红黑树 | 否 |
| HashMap | O(1) | O(1) | 哈希表+红黑树 | 否 |
| TreeMap | O(log n) | O(log n) | 红黑树 | 否 |
| LinkedListTree | O(log n) | O(log n) | 红黑树+链表 | 否 |
| LinkedListSet | O(1) | O(1) | 双向链表+哈希 | 否 |
| Queue | O(1) | O(n) | 数组/链表 | 否 |
小贴士:
- 查多用
ArrayList,改多用LinkedList。 - 去重选
HashSet,排序选TreeSet。 - 键值对用
HashMap,排序用TreeMap,缓存用LinkedHashMap。
# 7. 实战小例子
# 场景1:排行榜(TreeSet)
TreeSet<Integer> scores = new TreeSet<>();
scores.add(85); scores.add(92); scores.add(78);
System.out.println(scores); // [78, 85, 92]
2
3
# 场景2:LRU缓存(LinkedHashMap)
LinkedHashMap<String, Integer> cache = new LinkedHashMap<>(3, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 3; // 超3个淘汰最老的
}
};
cache.put("A", 1); cache.put("B", 2); cache.put("C", 3);
cache.get("A"); // 访问A
cache.put("D", 4); // 加D,淘汰B
System.out.println(cache); // {C=3, A=1, D=4}
2
3
4
5
6
7
8
9
10
# 8. 线程安全的集合类
JUC(java.util.concurrent)包提供了线程安全的集合类,适用于多线程环境。以下是常见的 JUC 集合及其特点:
- ConcurrentHashMap: 线程安全的 HashMap,分段锁(Java 7)或 CAS + 同步(Java 8),高并发读写。
- CopyOnWriteArrayList: 线程安全的 ArrayList,写时复制,适合读多写少。
- CopyOnWriteArraySet: 基于 CopyOnWriteArrayList 的线程安全 Set,无重复元素。
- ConcurrentLinkedQueue: 线程安全的无界队列,基于链表,使用 CAS 实现。
- BlockingQueue 及其实现(如 ArrayBlockingQueue、LinkedBlockingQueue):阻塞队列,支持生产者-消费者模式。
- ConcurrentSkipListMap: 线程安全的有序 Map,基于跳表,适合高并发排序。
- ConcurrentSkipListSet: 基于 ConcurrentSkipListMap 的线程安全有序 Set。
这些集合通过锁、CAS 或复制机制保证线程安全,性能比同步包装类(如 Collections.synchronizedList)更高。
# 9. 面试题
# 9.1 hashcode 和 equals 方法只重写一个行不行
**理论可以,但是不推荐!**是因为它们在集合类(如 HashMap、HashSet)中一起用于判断对象是否相等。如果只重写 equals() 而不同步更新 hashCode(),会导致集合行为异常,比如:
HashMap中无法正确找到键。HashSet中出现重复元素。
这是因为集合依赖 hashCode() 快速定位对象(分桶),再用 equals() 确认是否相等,二者必须保持一致性:如果两个对象 equals() 为 true,它们的 hashCode() 必须相等。
# 1. equals 和 hashCode 的关系
equals(): 定义两个对象是否“逻辑相等”,默认比较内存地址(==),可以重写为自定义规则。hashCode(): 返回对象的哈希码,默认基于内存地址,用于哈希表(如HashMap)快速定位。- 契约(Contract): Java 对象类的官方文档规定:
- 如果
a.equals(b)返回 true,则a.hashCode()必须等于b.hashCode()。 - 如果
a.hashCode() != b.hashCode(),则a.equals(b)必须返回 false。 - 反之不一定:
hashCode()相等,equals()可以不相等(哈希碰撞)。
- 如果
# 2. 为什么集合需要它们一致?
- 哈希表工作原理:
HashMap用hashCode()计算键的桶位置(索引)。- 在桶内用
equals()判断是否真正相等。
- 不一致的后果:
- 如果
equals()认为两个对象相等,但hashCode()不同,它们可能被放到不同桶,导致查找失败。 - 如果
hashCode()不重写,默认值可能不符合逻辑相等性,破坏集合的预期行为。
- 如果
# 3. 示例:不重写 hashCode 的问题
假设一个 Person 类,只重写 equals():
class Person {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person p = (Person) o;
return age == p.age && name.equals(p.name);
}
// 未重写 hashCode,默认用 Object 的实现
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
测试:
public static void main(String[] args) {
Person p1 = new Person("Alice", 25);
Person p2 = new Person("Alice", 25);
HashMap<Person, String> map = new HashMap<>();
map.put(p1, "Person 1");
System.out.println(map.get(p2)); // null
HashSet<Person> set = new HashSet<>();
set.add(p1);
set.add(p2);
System.out.println(set.size()); // 2
}
2
3
4
5
6
7
8
9
10
11
12
13
- 结果:
p1.equals(p2)为 true,但p1.hashCode() != p2.hashCode()(默认基于内存地址)。map.get(p2)返回 null,因为p2的哈希码定位到不同桶。set.size()为 2,重复添加,因为HashSet认为它们不相等。
# 4. 正确重写 hashCode
加上 hashCode():
@Override
public int hashCode() {
return 31 * name.hashCode() + age;
}
2
3
4
再次测试:
map.put(p1, "Person 1");
System.out.println(map.get(p2)); // "Person 1"
set.add(p1);
set.add(p2);
System.out.println(set.size()); // 1
2
3
4
5
结果:
p1.hashCode() == p2.hashCode(),定位到同一桶。equals()确认相等,HashMap和HashSet行为正确。
原因:
在 HashMap 中,会先通过对象的
hashCode()计算得到哈希值,用它来确定桶数组中的位置;如果该位置已有元素,则再通过equals()方法判断对象是否相等。
# 5. 为什么不自动重写?
- Java 不强制自动同步
hashCode(),因为:equals()的逻辑由开发者定义,hashCode()必须匹配自定义规则。- 自动生成可能不高效(比如基于所有字段)。
# 6. 重写 hashCode 的原则
- 一致性:
equals()相等的对象,hashCode()必须相等。 - 高效性: 尽量均匀分布,减少碰撞。
- 简单性: 常用方法:
31 * field1.hashCode() + field2(31 是质数,减少冲突)。
# 7. 什么时候不需要重写?
- 不使用哈希集合(
HashMap、HashSet),只用equals()比较时,可以不重写hashCode()。 - 但为了代码健壮性,建议始终保持一致。
# 10. 尾声:学会挑工具,代码更牛!
集合框架就是你的“武器库”,用得好,代码效率飞起,用不好,可能踩坑无数。记住这几点:
- 搞清楚底层(数组、链表、树),性能心里有数。
- 根据场景挑选手(查、改、排序、去重),别乱来。
- 线程安全要考虑,高并发别用非安全的家伙。
这篇教程带你从“门外汉”到“门清儿”,赶紧动手试试吧!有啥问题,随时来问我,咱们一起“开挂”学Java!