 JavaIO
JavaIO
# Java I/O 详解
# 1. 概述
Java 的 java.io 包提供了用于输入和输出的类和接口,用于处理文件操作、数据流、网络通信等。Java I/O 的设计基于**流(Stream)**的概念,通过流将数据从源(Source)传输到目标(Destination)。它支持多种数据源和目标,包括文件、内存缓冲区、网络套接字等。
# 1.1 I/O 的分类
Java I/O 主要分为两类:
- 字节流(Byte Stream):以字节为单位操作数据,适用于处理二进制数据(如图片、音频、视频等)。主要基类是
InputStream和OutputStream。 - 字符流(Character Stream):以字符为单位操作数据,适用于处理文本数据(如文本文件)。主要基类是
Reader和Writer。
此外,Java I/O 还支持:
- 缓冲流:通过缓冲减少对底层系统的直接访问,提高效率。
- 数据流:处理基本数据类型(如
int、double)和对象。 - 文件操作:直接操作文件和目录。
# 2. 文件概述
文件(File)是存储数据的地方。Java中主要涉及对文件的输入和输出(I/O)操作,相对于 Java 内存,从磁盘读取文件是输入(Input),向磁盘写入文件是输出(Output)。Java 提供了 java.io.File 类来表示文件和目录,并提供了一系列操作方法,如创建文件、创建文件夹、判断文件是否存在、获取文件大小等。
# 2.1 File对象结构
在 Java 中,java.io.File 类实现了两个接口:
Serializable接口(java.io.Serializable)Comparable<File>接口(java.lang.Comparable<File>)
# 2.11 Serializable接口
作用:
File类实现了Serializable,意味着File对象可以被序列化(即转换为字节流),并通过网络传输或存储到文件中。- 但需要注意的是,序列化
File对象并不会序列化文件的内容,它只会存储File对象的路径信息。
示例:File 对象的序列化与反序列化
import java.io.*;
public class FileSerializableExample {
public static void main(String[] args) {
File file = new File("test.txt");
// 序列化
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("fileObject.ser"))) {
oos.writeObject(file);
System.out.println("File 对象已序列化");
} catch (IOException e) {
e.printStackTrace();
}
// 反序列化
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("fileObject.ser"))) {
File deserializedFile = (File) ois.readObject();
System.out.println("反序列化后的 File 对象路径: " + deserializedFile.getAbsolutePath());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
注意:
- 反序列化后的
File对象仍然指向原来的文件路径,但不会恢复文件内容。 - 如果
test.txt文件在磁盘上被删除,反序列化后的File仍然存在,但file.exists()会返回false。
什么是序列化?
- 序列化:把对象转换成数据(字节流,json等),方便存储或传输。但是
Serializable序列化不推荐用于网络传输。具体因为:1. 只能 Java 内部使用,不支持跨语言。2. 体积大,性能低,数据包冗余。3. 存在安全漏洞,可能被攻击。 - 反序列化:把数据转换回对象。
# 2.12 Comparable<File> 接口
作用:
- 使
File对象支持自然排序,可以通过compareTo()方法比较两个File对象的路径名(按字典顺序)。 - 主要用于在
TreeSet<File>或Collections.sort(List<File>)中对文件对象排序。
示例:File 对象排序
import java.io.File;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class FileComparableExample {
public static void main(String[] args) {
List<File> fileList = new ArrayList<>();
fileList.add(new File("C:/Users/A.txt"));
fileList.add(new File("C:/Users/C.txt"));
fileList.add(new File("C:/Users/B.txt"));
// 按文件路径排序(字典序)
Collections.sort(fileList);
// 输出排序后的文件路径
for (File file : fileList) {
System.out.println(file.getPath());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
compareTo() 方法规则:
- 比较两个
File对象时,会按照文件路径的字符串字典顺序进行排序。 - 例如:
"A.txt"<"B.txt"<"C.txt"。 - 该方法区分大小写,
"a.txt"可能排在"A.txt"之后。
# 2.2 File 对象常用操作
java.io.File 是 Java 用于表示文件和目录的类,虽然它不能直接操作文件内容,但提供了文件管理的功能,例如创建、删除、判断文件是否存在等。其实这个过程涉及 磁盘和内存的交互
# 2.21 创建 File 对象
File 对象只是路径的抽象表示,不会真正创建文件或文件夹。
File file = new File("test.txt"); // 相对路径
File absoluteFile = new File("C:/Users/test.txt"); // 绝对路径
2
但这样不会真正创建文件! 需要调用 createNewFile() 或 mkdir() 进行创建。
# 2.22 文件/目录创建
(1)创建文件
import java.io.File;
import java.io.IOException;
public class CreateFileExample {
public static void main(String[] args) {
File file = new File("test.txt");
try {
if (file.createNewFile()) {
System.out.println("文件创建成功: " + file.getAbsolutePath());
} else {
System.out.println("文件已存在");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
✅ createNewFile() 只有在文件不存在时才会创建,否则返回 false。
(2)创建目录(文件夹)
File dir = new File("myDir");
// 创建单个目录
if (dir.mkdir()) {
System.out.println("目录创建成功");
}
// 创建多级目录
File multiLevelDir = new File("parentDir/childDir");
if (multiLevelDir.mkdirs()) {
System.out.println("多级目录创建成功");
}
2
3
4
5
6
7
8
9
10
11
12
✅ mkdir() 只能创建单个目录,mkdirs() 可以创建多级目录。
# 2.23 文件/目录的基本判断
File file = new File("test.txt");
System.out.println("是否存在: " + file.exists());
System.out.println("是否是文件: " + file.isFile());
System.out.println("是否是目录: " + file.isDirectory());
System.out.println("是否可读: " + file.canRead());
System.out.println("是否可写: " + file.canWrite());
System.out.println("是否可执行: " + file.canExecute());
2
3
4
5
6
7
8
✅ 文件必须存在,isFile() 和 isDirectory() 才有意义。
# 2.24 获取文件信息
File file = new File("test.txt");
System.out.println("文件路径: " + file.getPath());
System.out.println("绝对路径: " + file.getAbsolutePath());
System.out.println("父级目录: " + file.getParent());
System.out.println("文件大小 (字节): " + file.length());
System.out.println("最后修改时间: " + new java.util.Date(file.lastModified()));
2
3
4
5
6
7
✅ length() 只能获取普通文件的大小,不能用于文件夹。
# 2.25 文件/目录删除
File file = new File("test.txt");
if (file.delete()) {
System.out.println("文件删除成功");
} else {
System.out.println("文件删除失败");
}
2
3
4
5
6
7
✅ 目录只有为空时才能删除,若要删除非空目录,需使用递归。
删除非空目录(递归实现)
public static void deleteDirectory(File dir) {
if (dir.isDirectory()) {
for (File file : dir.listFiles()) {
deleteDirectory(file); // 递归删除子文件和子目录
}
}
dir.delete();
}
2
3
4
5
6
7
8
# 2.26 遍历文件夹
File dir = new File("C:/Users");
if (dir.isDirectory()) {
File[] files = dir.listFiles();
for (File f : files) {
System.out.println(f.getName());
}
}
2
3
4
5
6
7
8
✅ listFiles() 返回 File[],可以获取目录下的所有文件和子目录。
# 3. 从文件和流关系
# 3.1 为什么需要流?
计算机中的文件是静态存储的数据,而程序运行时通常需要动态地读取或写入数据。直接操作文件不仅不方便,而且效率低下。因此,流(Stream) 作为数据的通道,让文件的数据可以像“水流”一样被程序处理。
可以把 文件 和 流 的关系类比成:
- 文件: 一个水库,存储着大量数据(静态)。
- 流: 一条水管,让程序能够获取或存入数据(动态)。
例如:
- 输入流(InputStream/Reader):从文件读取数据到程序,就像从水库取水。
- 输出流(OutputStream/Writer):将数据写入文件,就像向水库注水。
# 3.2 文件如何转为流?
在 Java 中,操作文件的流主要分为两类:
- 字节流(InputStream/OutputStream):用于处理二进制文件,如图片、音频、视频等。
- 字符流(Reader/Writer):用于处理文本文件,如
.txt文件。
# 4. 核心类和接口
以下是 java.io 包中常用的核心类和接口:
# 4.1 字节流
InputStream:所有字节输入流的抽象基类,提供从数据源读取字节的方法。- 常用子类:
FileInputStream:从文件中读取字节。ByteArrayInputStream:从字节数组中读取数据。BufferedInputStream:缓冲输入流,减少对底层文件系统的直接调用。
- 常用子类:
OutputStream:所有字节输出流的抽象基类,提供向目标写入字节的方法。- 常用子类:
FileOutputStream:向文件写入字节。ByteArrayOutputStream:将数据写入字节数组。BufferedOutputStream:缓冲输出流。
- 常用子类:
# 4.2 字符流
Reader:所有字符输入流的抽象基类,提供读取字符的方法。- 常用子类:
FileReader:从文件中读取字符。BufferedReader:缓冲字符输入流,提供readLine()方法读取整行文本。InputStreamReader:将字节流转换为字符流(桥梁类)。
- 常用子类:
Writer:所有字符输出流的抽象基类,提供写入字符的方法。- 常用子类:
FileWriter:向文件写入字符。BufferedWriter:缓冲字符输出流。OutputStreamWriter:将字符流转换为字节流(桥梁类)。
- 常用子类:
# 4.3 文件操作
File:表示文件或目录的抽象路径,提供文件操作(如创建、删除、重命名)。RandomAccessFile:支持随机读写文件,可以在文件中任意位置读写数据。
# 4.4 数据流和对象流
DataInputStream/DataOutputStream:读写基本数据类型(如int、float)。ObjectInputStream/ObjectOutputStream:读写对象(序列化和反序列化)。
# 5. 基本操作和使用场景
# 5.1 文件读取
- 字节流示例(读取二进制文件):
import java.io.FileInputStream;
import java.io.IOException;
public class FileReadExample {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("example.bin")) {
int byteData;
while ((byteData = fis.read()) != -1) { // 读取单个字节
System.out.print((char) byteData);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 字符流示例(读取文本文件):
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class TextReadExample {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new FileReader("example.txt"))) {
String line;
while ((line = br.readLine()) != null) { // 逐行读取
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 5.2 文件写入
- 字节流示例(写入二进制文件):
import java.io.FileOutputStream;
import java.io.IOException;
public class FileWriteExample {
public static void main(String[] args) {
try (FileOutputStream fos = new FileOutputStream("output.bin")) {
String data = "Hello, Java I/O!";
fos.write(data.getBytes()); // 写入字节数组
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
- 字符流示例(写入文本文件):
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class TextWriteExample {
public static void main(String[] args) {
try (BufferedWriter bw = new BufferedWriter(new FileWriter("output.txt"))) {
bw.write("Hello, Java I/O!"); // 写入字符串
bw.newLine(); // 新行
bw.write("This is a test.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 5.3 对象序列化
- 序列化示例(保存对象到文件):
import java.io.*;
public class SerializationExample {
public static void main(String[] args) {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.dat"))) {
Person person = new Person("Alice", 25);
oos.writeObject(person); // 序列化对象
} catch (IOException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 反序列化示例(从文件读取对象):
import java.io.*;
public class DeserializationExample {
public static void main(String[] args) {
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.dat"))) {
Person person = (Person) ois.readObject(); // 反序列化
System.out.println("Name: " + person.name + ", Age: " + person.age);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
是的,在实际开发中,缓冲流(Buffered Stream) 被广泛使用,因为它可以 提高 I/O 读写性能,减少直接访问文件或网络的次数,提高程序的运行效率。
# 6. 缓冲流
# 6.1 直接使用流的问题
如果直接使用 FileInputStream 或 FileOutputStream 读取或写入文件,每次 read() 或 write() 操作都会触发磁盘 I/O,这会导致性能较低。例如:
FileInputStream fis = new FileInputStream("example.txt");
int data;
while ((data = fis.read()) != -1) { // 每次读取一个字节
System.out.print((char) data);
}
fis.close();
2
3
4
5
6
问题:
- 每次
read()只读取 一个字节,磁盘 I/O 频繁调用,性能低下。
解决方案:使用缓冲流
缓冲流使用 内存缓冲区 作为中转,每次 批量读取或写入数据,减少直接访问磁盘的次数,提升性能。
BufferedInputStream/BufferedOutputStream(缓冲字节流)BufferedReader/BufferedWriter(缓冲字符流)
# 6.2 如何使用缓冲流?
# (1)使用 BufferedInputStream 读取文件
import java.io.*;
public class BufferedStreamExample {
public static void main(String[] args) throws IOException {
File file = new File("example.txt");
// 用 BufferedInputStream 包装 FileInputStream
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
int data;
while ((data = bis.read()) != -1) { // 从缓冲区读取数据
System.out.print((char) data);
}
bis.close(); // 关闭流
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
改进点:
BufferedInputStream先从磁盘 批量读取数据 存入缓冲区,程序再从缓冲区 逐字节读取,减少磁盘 I/O 频率,提高性能。
# (2)使用 BufferedReader 读取文本
相比 BufferedInputStream 逐字节读取,BufferedReader 可以按行读取文本,更适合处理文本文件:
import java.io.*;
public class BufferedReaderExample {
public static void main(String[] args) throws IOException {
File file = new File("example.txt");
// 用 BufferedReader 包装 FileReader
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
String line;
while ((line = br.readLine()) != null) { // 按行读取
System.out.println(line);
}
br.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
优点:
readLine()直接读取一整行,避免每次read()读取一个字符,提高效率。
# (3)使用 BufferedOutputStream 写入文件
写入文件时,如果不使用缓冲流,每次 write() 调用都会触发磁盘 I/O,而缓冲流能 批量写入,减少磁盘操作:
import java.io.*;
public class BufferedOutputStreamExample {
public static void main(String[] args) throws IOException {
File file = new File("output.txt");
// 用 BufferedOutputStream 包装 FileOutputStream
FileOutputStream fos = new FileOutputStream(file);
BufferedOutputStream bos = new BufferedOutputStream(fos);
String content = "Hello, BufferedOutputStream!";
bos.write(content.getBytes()); // 批量写入数据
bos.flush(); // 确保数据写入文件
bos.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
改进点:
BufferedOutputStream先写入缓冲区,等缓冲区满了才写入文件,减少磁盘 I/O。flush()强制写入缓冲区数据,避免数据丢失。
# (4)使用 BufferedWriter 写入文本
对于文本写入,可以使用 BufferedWriter,它支持 按行写入:
import java.io.*;
public class BufferedWriterExample {
public static void main(String[] args) throws IOException {
File file = new File("output.txt");
// 用 BufferedWriter 包装 FileWriter
FileWriter fw = new FileWriter(file);
BufferedWriter bw = new BufferedWriter(fw);
bw.write("Hello, BufferedWriter!");
bw.newLine(); // 写入换行符
bw.write("This is another line.");
bw.flush();
bw.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
优点:
newLine()直接写入换行符,跨平台兼容。flush()确保缓冲区数据写入文件。
# 7. 设计模式和特性
# 7.1 装饰者模式
Java I/O 使用装饰者模式(Decorator Pattern),允许通过包装类增强流的功能。例如:
BufferedInputStream装饰FileInputStream,提供缓冲功能。DataInputStream装饰BufferedInputStream,增加读写基本数据类型的能力。
示例:
FileInputStream fis = new FileInputStream("data.bin");
BufferedInputStream bis = new BufferedInputStream(fis); // 缓冲装饰
DataInputStream dis = new DataInputStream(bis); // 数据类型装饰
int value = dis.readInt(); // 读取整数
2
3
4
# 7.2 异常处理
I/O 操作通常涉及外部资源(如文件、网络),因此需要处理 IOException。推荐使用 try-with-resources 语句,确保资源正确关闭。
# 7.3 性能优化
- 使用缓冲流(如
BufferedReader、BufferedOutputStream)减少底层系统调用。 - 对于大数据量操作,合理设置缓冲区大小。
# 8. BIO、NIO 和 AIO
我们可以根据流的场景又可以分为
- 磁盘流(Disk Stream)和 内存流(Memory Stream)主要涉及本地数据的读写,如 文件操作(File I/O)。
- 网络流(Network Stream)则用于 远程数据传输,如 HTTP 通信、Socket 通信等。
在 Java 中,I/O 操作(如 网络通信、文件读写)对系统的 性能和并发能力 有着重要影响。三种主要的 I/O 模型:BIO(同步阻塞 I/O)、NIO(同步非阻塞 I/O)、AIO(异步非阻塞 I/O),它们在设计上各有不同,适用于不同的应用场景。
# socket连接建立时,内核发生了什么?
**socket()**系统调用:
- 创建一个socket,内核里会生成一个socket对象(struct socket)。
- 这个对象里会关联一堆东西,比如:
- 文件描述符(fd)
- 协议族(TCP/UDP)
- 发送缓冲区(send buffer)
- 接收缓冲区(recv buffer)
- 还有指向协议控制块(TCP层面的控制块,比如
struct tcp_sock)
**bind()**系统调用(服务器端):
- 把这个socket绑定到某个本地IP和端口。
**listen()**系统调用(服务器端):
- 告诉内核,这个socket要变成监听状态了(监听连接)。
- 内核为这个socket创建两个队列:
- 半连接队列(syn queue):还没完成三次握手的连接。
- 全连接队列(accept queue):三次握手完成,等待应用程序
accept()拿走的连接。
**connect()**系统调用(客户端):
- 发起TCP三次握手。
- 三次握手完成后,服务器端内核会把连接放入全连接队列。
**accept()**系统调用(服务器端):
- 应用调用
accept()时,从全连接队列中取出一个连接。 - 创建一个新的socket对象(代表新连接)。
- 应用调用
# 8.1 BIO(Blocking I/O)
BIO(Blocking I/O)是 Java 中最传统的 I/O 模型。它的特点是:每个连接都会占用一个独立的线程,并且该线程会在执行 I/O 操作时被阻塞,直到数据准备好或操作完成。
# 8.11 BIO 工作原理
在 BIO 中,服务器需要 为每个客户端连接创建一个线程,每个线程都会进行阻塞式 I/O 操作,直到连接关闭或数据完成读取。这种模型的缺点在于,当并发量增加时,每个连接都需要一个线程,造成 线程资源浪费 和 上下文切换 开销。
调用I/O相关API(如accept()、read()、write())时,如果资源不可用,会阻塞,线程挂起,直到资源就绪。
accept()阻塞:等新连接,是在等三次握手完成的新连接排队到accept队列。read()阻塞:等数据到达,用户态切换到内核态阻塞,监控fd文件状态变换。write()阻塞:等缓冲区可写,同理。
# 8.12 BIO 示例:
int listenfd = socket(...);
bind(listenfd, ...);
listen(listenfd, SOMAXCONN);
while (1) {
int connfd = accept(listenfd, NULL, NULL); // 阻塞,等新连接
read(connfd, buffer, sizeof(buffer)); // 阻塞,等数据
write(connfd, buffer, sizeof(buffer)); // 阻塞,等可写
}
2
3
4
5
6
7
8
9
- 每个动作可能阻塞,线程被挂起。
- 服务端吞吐量受限于线程数,性能差。
- 常见优化:线程池模型(一个线程池去处理多个连接)。
# 8.2 NIO(Non-blocking I/O)
NIO(Non-blocking I/O)是相对于传统 BIO 的 非阻塞 I/O 模型,它通过 Selector(选择器) 和 Channel(通道) 的方式,使得一个线程可以同时处理多个客户端连接。NIO 模型使用事件驱动和非阻塞的方式来提高并发能力。
通过一个线程同时管理大量连接,不阻塞在单个I/O操作上。
- 连接设置成非阻塞模式。
- 依靠select/poll/epoll来统一监听所有fd。
- 有事件时才处理,无事件时可以继续监听其他fd。
# 8.21 NIO 工作原理
在 NIO 中,一个线程可以监听多个通道(Channel),并使用 Selector 来处理多个连接。每个通道的 I/O 操作都是非阻塞的,线程只有在有事件发生时才会去处理 I/O 操作。NIO 提供了事件驱动的 I/O 操作,极大地减少了每个连接的线程开销。
# 8.22 NIO 示例
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.bind(new InetSocketAddress(port));
serverChannel.configureBlocking(false);
Selector selector = Selector.open();
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(); // 阻塞,监听所有注册fd的事件
Set<SelectionKey> keys = selector.selectedKeys();
for (SelectionKey key : keys) {
if (key.isAcceptable()) {
SocketChannel client = serverChannel.accept(); // 接受新连接
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel client = (SocketChannel) key.channel();
// 读数据
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 优点:
- 一个线程可以处理多个连接,减少了线程的开销,适合高并发场景。
- 缺点:
- 相比 BIO,NIO 的编程模型复杂,需要理解 Selector 和 Channel 的使用。
BIO靠人海战术(线程堆积)解决并发,NIO靠机制(事件监听)解决并发;select/poll/epoll是I/O多路复用的具体实现方式,epoll效率最高。
# 8.3 AIO(Asynchronous I/O)
AIO(Asynchronous I/O)是 Java 7 引入的一种 异步 I/O 模型。与 NIO 的非阻塞模型不同,AIO 提供了一种真正的 异步处理方式,即 I/O 操作不会阻塞当前线程,而是通过回调通知机制在操作完成时通知应用程序。
# 8.31 AIO 工作原理
AIO 模型中的 I/O 操作在后台线程中执行,并且通过 回调函数(callback)通知应用程序操作完成。应用程序无需关注 I/O 操作的执行过程,而只需关注最终的结果。这使得 AIO 在处理大量 I/O 请求时比 NIO 更加高效。
# 8.32 AIO 示例
AsynchronousServerSocketChannel serverSocket = AsynchronousServerSocketChannel.open();
serverSocket.bind(new InetSocketAddress(8080));
serverSocket.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
public void completed(AsynchronousSocketChannel result, Void attachment) {
// 处理客户端请求
}
public void failed(Throwable exc, Void attachment) {
exc.printStackTrace();
}
});
2
3
4
5
6
7
8
9
10
- 优点:
- I/O 操作完全异步,CPU 和内存利用效率高,适合高并发、大量短连接的场景。
- 不需要一直轮询 I/O 事件或阻塞线程,效率更高。
- 缺点:
- 编程模型复杂,理解和使用异步回调可能会增加开发难度。
# 8.4 BIO、NIO 和 AIO 的对比
| 特性 | BIO | NIO | AIO |
|---|---|---|---|
| 线程模型 | 一请求一个线程(阻塞) | 多连接复用一个线程(非阻塞) | 完全异步,通过回调处理(非阻塞) |
| 操作方式 | 阻塞式(每个请求都阻塞等待) | 非阻塞式(通过 Selector 轮询) | 完全异步(后台线程处理,回调通知) |
| 适用场景 | 小流量应用,低并发 | 高并发应用(如 Netty、Nginx) | 高并发、大量短连接(如 WebSocket) |
| 实现复杂度 | 简单 | 较复杂,需要理解 Selector 和 Channel | 较复杂,需要理解异步回调机制 |
| 优点 | 简单实现,适用于低并发场景 | 高并发处理,线程复用,适合大规模并发 | 极高的效率,适用于高并发场景 |
| 缺点 | 高并发时性能差,资源消耗大 | 编程复杂,操作可能繁琐 | 编程复杂,异步回调可能难以理解 |
# 9. I/O多路复用机制
在高并发场景下,服务器往往需要同时处理多个客户端连接。传统的阻塞式 I/O 已难以满足性能需求,于是便有了 I/O 多路复用(I/O multiplexing) 的机制,它允许一个线程或进程监听多个文件描述符(如 socket),以便及时响应其中任何一个就绪事件。
# 9.1 select 和 poll
select 是最早提出的 I/O 多路复用机制,其基本思想是:
将所有感兴趣的文件描述符放入一个集合中,并调用 select 函数,让内核检查集合中哪些文件描述符已经就绪。
# 工作机制如
- 用户将一组文件描述符集合传入内核;
- 内核遍历集合,检查是否有事件发生;
- 将就绪状态更新后,再将整个集合拷贝回用户空间;
- 用户再次遍历集合,找出已就绪的描述符,进行处理。
因此,select 会产生:
- 两次拷贝(用户态 → 内核态,再从内核态 → 用户态);
- 两次遍历(内核遍历一次、用户再次遍历一次);
- 使用固定大小的位图(bitmap)来存储描述符集合,在 Linux 上受
FD_SETSIZE限制,默认最大监听 1024 个文件描述符。
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(sockfd, &readfds);
select(maxfd + 1, &readfds, NULL, NULL, NULL);
2
3
4
# poll 的改进
poll 用链表或动态数组代替位图结构,支持任意数量的文件描述符,不受 FD_SETSIZE 限制。但其本质机制与 select 一致:
- 仍需线性遍历所有描述符,时间复杂度为 O(n);
- 每次调用仍需将整个结构从用户态拷贝到内核态;
- 并未解决在高并发场景下效率低下的问题。
# 9.2 epoll(Linux 特有)
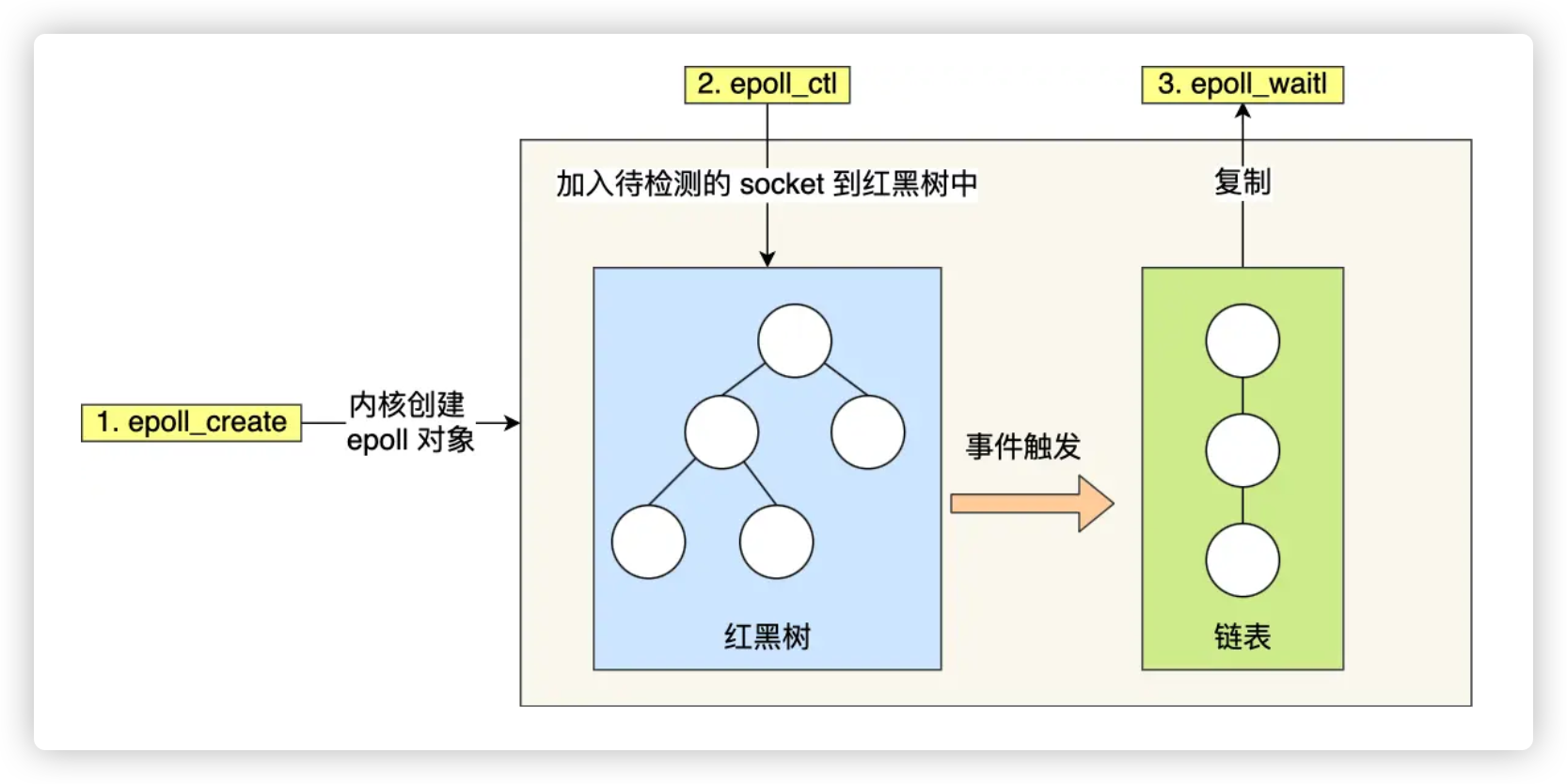
为了解决 select/poll 的性能瓶颈,Linux 提出了 epoll 机制。它采用事件驱动模型,结合高效的数据结构(红黑树与就绪链表),能在大并发场景下提供更高的性能。
# epoll 使用方式
int epfd = epoll_create(size); // 创建 epoll 实例
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, ...); // 注册感兴趣的 socket
while (1) {
int n = epoll_wait(epfd, events, ...); // 等待事件
for (int i = 0; i < n; i++) {
// 处理 events[i].data.fd
}
}
2
3
4
5
6
7
8
# epoll 的两大优势
1. 内核空间维护红黑树:
- 所有注册的 socket 被组织进内核中的红黑树中;
- 增删查复杂度为 O(log n),高效管理监听集合;
- 只需注册一次,不必每次重复传入所有文件描述符,大幅减少了用户态与内核态之间的数据拷贝。
2. 使用就绪事件列表:
- epoll 内核端维护一个就绪事件链表;
- 当某个 socket 上有事件发生时,内核通过回调机制直接将其挂入就绪列表;
epoll_wait()调用时只返回有事件的 socket,不再需要扫描整个监听集合;- 实现了真正的事件驱动机制,提高检测效率。
# epoll 整体架构图
# 9.3 总结对比
| 特性 | select | poll | epoll |
|---|---|---|---|
| 数据结构 | 位图 | 动态数组 | 红黑树 + 就绪链表 |
| 最大连接数 | 1024(默认) | 无限制 | 无限制(仅受系统限制) |
| 时间复杂度 | O(n) | O(n) | O(log n) + O(1) |
| 是否支持事件驱动 | 否 | 否 | 是 |
| 用户/内核拷贝 | 每次全量拷贝 | 每次全量拷贝 | 注册一次,复用等待 |