 使用SVM进行二分类
使用SVM进行二分类
# 使用SVM进行二分类:代码详解
# 介绍
在机器学习中,支持向量机(Support Vector Machine,SVM)是一种强大的算法,可用于二分类问题。本博客将详细介绍如何使用Python和Scikit-Learn库来实现一个SVM模型,以解决一个典型的二分类问题。我们将一步一步地分析代码的结构、逻辑、关键参数和方法使用说明,以帮助读者理解和应用这一算法。
# 步骤1:导入必要的库
首先,我们需要导入所需的Python库,包括NumPy、Matplotlib、Pandas以及Scikit-Learn的相关模块。这些库将帮助我们进行数据处理、可视化和建模。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix, classification_report
from matplotlib.colors import ListedColormap
2
3
4
5
6
7
8
# 步骤2:导入数据集
在这一步,我们将导入我们的数据集,该数据集位于文件"Social_Network_Ads.csv"中。数据集通常包含了特征(features)和目标变量(target variable)。你可以在Social_Network_Ads.csv下载数据集。
这个数据集看起来像这样:
| Age | EstimatedSalary | Purchased |
|---|---|---|
| 19 | 19000 | 0 |
| 35 | 20000 | 0 |
| ... | ... | ... |
我们的目标是根据年龄(Age)和估计工资(EstimatedSalary)来预测用户是否购买了某个产品(Purchased)。我们将数据集拆分为特征(X)和目标变量(y)。
# 导入数据集
dataset = pd.read_csv('../data/Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
2
3
4
# 步骤3:数据预处理
在进行建模之前,我们需要对数据进行一些预处理,包括拆分数据集为训练集和测试集、特征缩放等。这有助于提高模型的性能。
# 3.1 拆分数据集
我们使用train_test_split函数将数据集拆分为训练集和测试集,通常将一部分数据用于模型的训练,另一部分用于模型的测试。
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
2
# 3.2 特征缩放
在许多机器学习算法中,特征缩放是一项重要的预处理步骤。我们使用StandardScaler来标准化特征,确保它们在相似的尺度上。
# 特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
2
3
4
理解了,我会详细说明一些关键方法和参数的使用。
# 步骤4:建立SVM模型
在这一步中,我们建立了支持向量机(SVM)模型,这是解决分类问题的核心步骤。我们使用Scikit-Learn库中的SVC类来实现这一步骤。以下是一些关键的方法和参数的详细说明:
# 4.1 SVC 类
classifier = SVC(kernel='linear', random_state=0)
SVC是支持向量机分类器的类。kernel参数:这是SVM模型的核函数,控制数据在高维空间中的映射。在此示例中,我们选择了线性核函数,即kernel='linear'。其他常见的核函数包括'rbf'(径向基函数)和'poly'(多项式核函数),具体选择取决于问题的性质。random_state参数:这是一个随机种子,用于初始化模型的随机性。它可以帮助确保每次运行代码时得到相同的结果,以便结果的可重复性。
# 步骤5:模型预测
我们使用训练好的SVM模型对测试集进行预测。
# 在测试集上进行预测
y_pred = classifier.predict(X_test)
2
# 步骤6:评估模型性能
在这一步中,我们评估了SVM模型的性能,了解模型的准确性和其他性能指标。我们使用了混淆矩阵和分类报告来完成这项任务。
# 6.1 混淆矩阵(Confusion Matrix)
cm = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(cm)
2
3
confusion_matrix函数接受两个参数:真实的目标值y_test和模型预测的目标值y_pred。- 混淆矩阵是一个二维数组,它展示了模型的分类性能。它的四个元素分别是真正例(True Positives,TP)、真负例(True Negatives,TN)、假正例(False Positives,FP)和假负例(False Negatives,FN)的数量。这些元素用于计算精确度、召回率等性能指标。
# 6.2 分类报告(Classification Report)
print("\n分类报告:")
print(classification_report(y_test, y_pred))
2
classification_report函数接受两个参数:真实的目标值y_test和模型预测的目标值y_pred。- 分类报告提供了关于模型性能的详细信息,包括精确度(Precision)、召回率(Recall)、F1分数(F1-score)等。它对每个类别进行了单独的评估,并提供了加权平均值(weighted average)。
这些方法和参数是评估分类模型性能时常用的工具,可以帮助我们理解模型的强项和弱项,以便进一步优化和改进模型。
# 步骤7:可视化结果
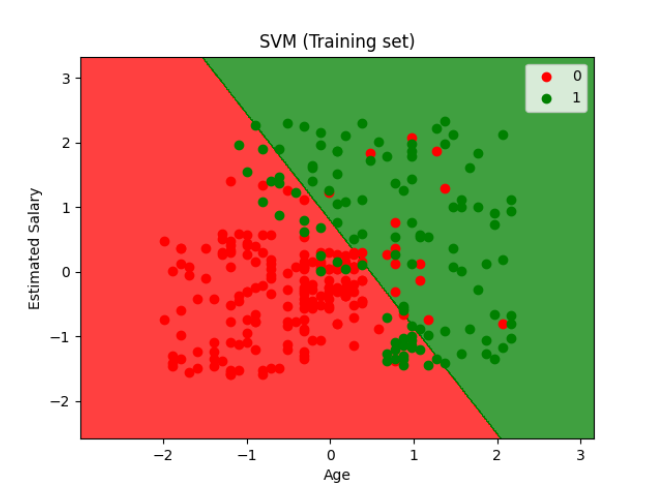
最后,我们通过可视化来展示模型的性能。我们使用Matplotlib来绘制训练集和测试集的决策边界和数据点。
# 可视化训练集结果
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start=X_set[:, 0].min() - 1, stop=X_set[:, 0].max() + 1, step=0.01),
np.arange(start=X_set[:, 1].min() - 1, stop=X_set[:, 1].max() + 1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha=0.75, cmap=ListedColormap(['r', 'g']))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
color=ListedColormap(['r', 'g'])(i), label=j) # 使用color参数指定颜色
plt.title('SVM (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
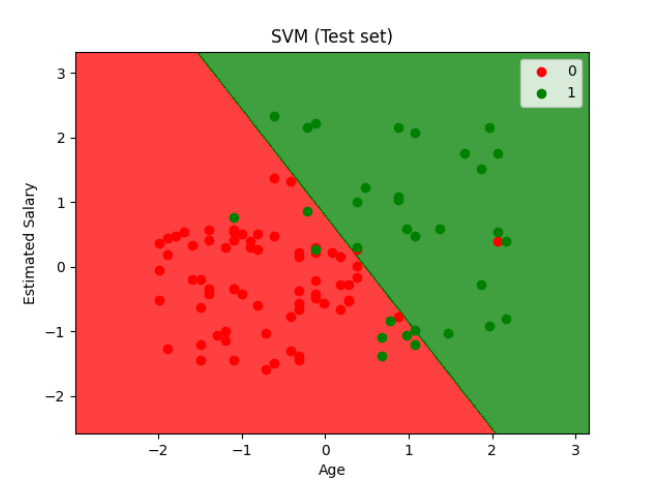
# 可视化测试集结果
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start=X_set[:, 0].min() - 1, stop=X_set[:, 0].max() + 1, step=0.01),
np.arange(start=X_set[:, 1].min() - 1, stop=X_set[:, 1].max() + 1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha=0.75, cmap=ListedColormap(['r', 'g']))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
color=ListedColormap(['r', 'g'])(i), label=j) # 使用color参数指定颜色
plt.title('SVM (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
在这两个步骤中,我们首先创建了网格来绘制决策边界,然后使用plt.contourf绘制决策区域,最后使用plt.scatter来绘制数据点并通过color参数指定颜色。
这就是使用SVM进行二分类的完整过程。通过这个博客,我们希望读者能够理解SVM模型的构建和使用,并能够将其应用到其他类似的问题中。这个示例中,我们解决了一个简单的问题,但SVM在更复杂的问题中也是一个有力的工具。
← 支持向量机(SVM) 决策树→